Introduction
Dans cet article, nous allons explorer la création d’un POC (Proof of Concept) pour un système de RAG (Retrieval Augmented Generation) en utilisant Node.js, une base de données vectorielle ChromaDB, et le modèle de langage Llama3 via Ollama.
Qu’est-ce qu’une RAG ?
Une RAG, ou Retrieval Augmented Generation, est une technique qui combine la recherche d’informations pertinentes dans une base de données (retrieval) avec la génération de texte (generation) pour fournir des réponses plus précises et contextuelles. En d’autres termes, un RAG peut récupérer des données spécifiques et utiliser un modèle de langage pour générer une réponse en se basant sur ces données, ce qui le rend particulièrement utile pour des applications nécessitant des réponses détaillées et informées.
Qu’est-ce que ChromaDB et une base de données vectorielle ?
ChromaDB est une base de données vectorielle, un type de base de données spécialement conçu pour stocker et rechercher des vecteurs. Les vecteurs sont des représentations numériques de données (comme des textes ou des images) qui permettent de mesurer la similarité entre ces données. Dans le cas présent, ChromaDB est utilisée pour rechercher des phrases similaires à la question posée, ce qui aide à récupérer les informations les plus pertinentes pour générer une réponse précise.
Qu’est-ce qu’Ollama ?
Ollama est un outil qui facilite l’utilisation de modèles de langage de grande taille (LLM) comme Llama3. Il permet de gérer facilement ces modèles et de les intégrer dans des applications. Dans ce POC, Ollama est utilisé pour générer des réponses basées sur les données récupérées par ChromaDB, ajoutant une couche de compréhension et de génération de texte naturel.
Qu’est-ce qu’un LLM (Llama3) ?
Un LLM (Large Language Model), comme Llama3, est un modèle d’intelligence artificielle entraîné sur de vastes quantités de données textuelles. Ces modèles peuvent comprendre et générer du texte en langage naturel de manière très sophistiquée. Dans ce POC, Llama3 est utilisé pour transformer les données récupérées en réponses claires et pertinentes, améliorant ainsi l’expérience utilisateur en fournissant des informations complètes et bien formulées.
Nous allons détailler chaque étape pour vous permettre de reproduire ce POC facilement.
Prérequis
Avant de commencer, assurez-vous d’avoir les éléments suivants installés sur votre machine :
- Ubuntu 22.04 (mais cela devrait fonctionner sur les autres OS)
- Node.js (version 20 ou supérieure)
- npm (Node Package Manager)
- Python3 (pour lancer le serveur ChromaDB)
Objectif
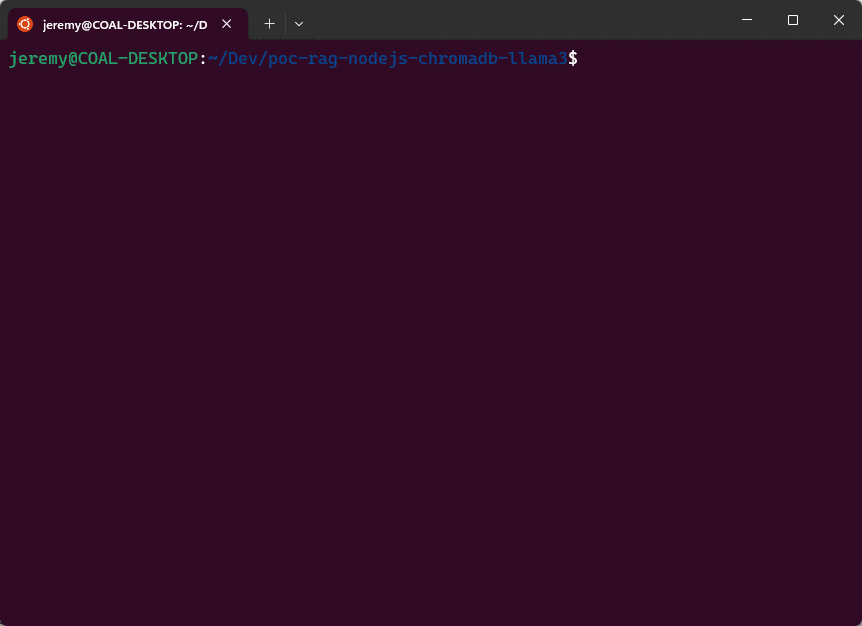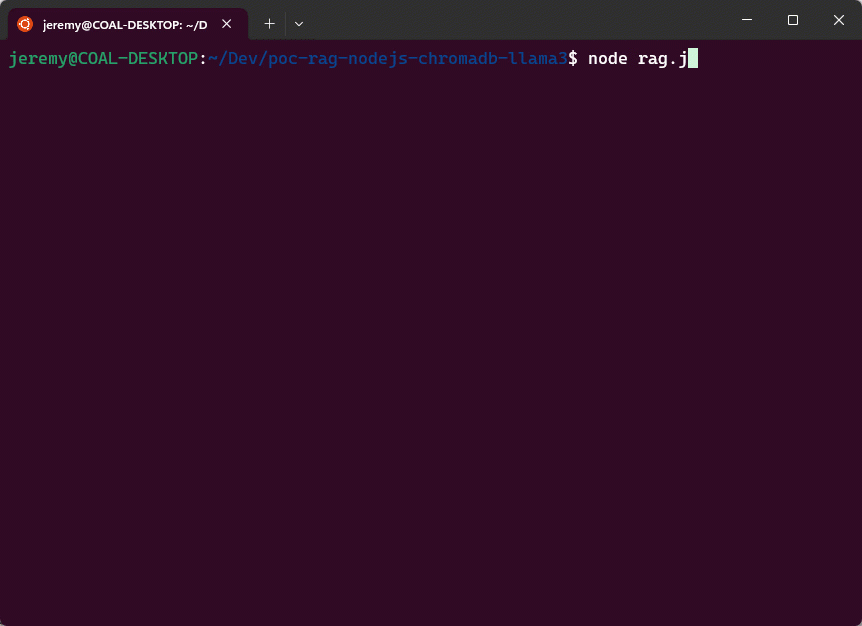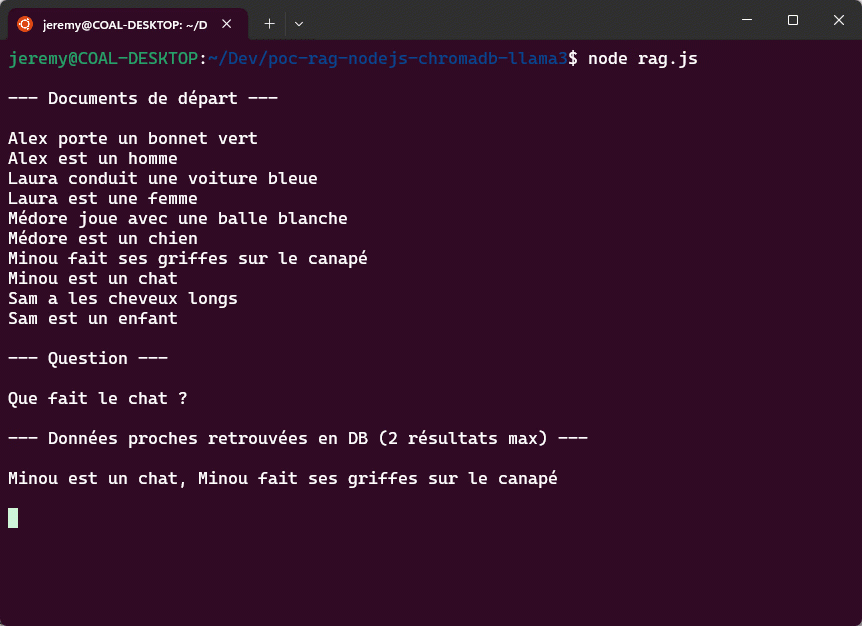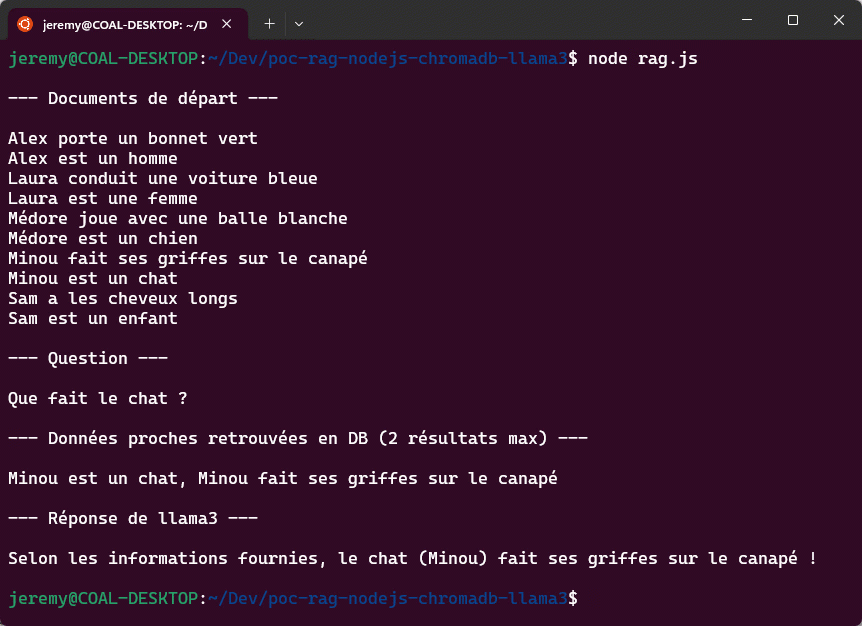
Notre dataset contient des informations sur des personnes et des animaux. Nous allons utiliser ChromaDB pour stocker ces informations et rechercher des données pertinentes en fonction de la question posée. Ensuite, nous utiliserons Ollama avec le modèle Llama3 pour générer une réponse basée sur les données récupérées. Voici les informations dont nous disposons :
“Alex porte un bonnet vert”
“Alex est un homme”
“Laura conduit une voiture bleue”
“Laura est une femme”
“Médore joue avec une balle blanche”
“Médore est un chien”
“Minou fait ses griffes sur le canapé”
“Minou est un chat”
“Sam a les cheveux longs”
“Sam est un enfant”
La question posée sera : “Que fait le chat ?”. Nous allons rechercher des données similaires dans notre dataset, puis utiliser Ollama avec Llama3 pour générer une réponse basée sur ces données.
Principe de fonctionnement de notre RAG

Étape 1 : Installer ChromaDB
Commencez par installer ChromaDB sur votre système Linux Ubuntu :
1 | $ pip install chromadb |
Démarrer le serveur ChromaDB :
1 | $ mkdir ~/rag-app |
Étape 2 : Installer Ollama et Llama3
Nous allons maintenant installer Ollama, Llama3 et démarrer le service (dans une autre console) :
1 | $ curl -fsSL https://ollama.com/install.sh | sh |
Étape 3 : Installer les dépendances pour Node.js
Nous allons maintenant créer un script en Node.js pour interagir avec ChromaDB et Ollama. Commençons par installer les packages nécessaires :
1 | $ cd ~/rag-app |
Étape 3 : Initialiser ChromaDB et Ollama (rag.js)
1 | const ollama = require('ollama').default |
Étape 4 : Définir les Données et la Collection
Ajoutons les documents et la collection à ChromaDB (dataset) :
1 | const collectionName = 'docs' |
Étape 5 : Supprimer et Créer une Collection
Nous allons ajouter les fonctions pour supprimer et créer une nouvelle collection dans ChromaDB :
1 | // on supprime la collection si elle existe |
Étape 6 : Ajouter des Documents à la Collection
Ajoutons les documents dans la collection que nous venons de créer :
1 | // on ajoute les documents à la collection |
Étape 7 : Recherche par Similarité
Implémentons la recherche par similarité dans la collection :
1 | // on recherche dans la collection par similarité |
Étape 8 : Générer la Réponse avec Ollama / LLama3
Nous allons maintenant utiliser Ollama pour générer une réponse à partir des données trouvées :
1 | // on génère la réponse à partir des données trouvées |
Étape 9 : Exécuter les Fonctions
Pour finir, créons une fonction principale pour exécuter toutes les étapes séquentiellement:
1 | // on exécute les fonctions |
Le programme complet
1 | const ollama = require('ollama').default |
Vous pouvez retrouver le code source complet sur Github
Conclusion
En suivant ces étapes, vous pouvez créer un POC de RAG en utilisant Node.js, ChromaDB et Llama3 via Ollama. Ce processus vous permet d’explorer la puissance des bases de données vectorielles et des modèles de langage avancés pour améliorer vos applications web avec des capacités de génération de réponses enrichies par la récupération d’informations pertinentes.
N’hésitez pas à adapter ce script à vos propres besoins et à explorer d’autres fonctionnalités de ChromaDB et Ollama pour aller plus loin dans l’innovation technologique.
Jérémy @ Code Alchimie
Une idée de business en ligne ? Un saas à développer ? Une boutique en ligne à créer ?
Essayer mon-plan-action.fr pour vous aider à démarrer votre projet en ligne.