Mais un kernel temps réel ne suffit pas : il faut aussi éviter les mécanismes de synchronisation qui bloquent.
Aujourd’hui, je vous présente les ring buffers lock-free, la solution pour une communication inter-threads sans aucun blocage, parfaite pour le temps réel strict.
Le problème des mutex et sémaphores en temps réel
Scénario catastrophe : l’inversion de priorité
Prenons le cas de deux threads :
Thread
Priorité
Rôle
Thread A
80 (haute)
Master EtherCAT, cycle de 1 ms
Thread B
60 (basse)
Communication UDP avec PC
Les deux threads partagent des données via un mutex. Voici ce qui peut se passer :
1 2 3 4 5 6
t=0ms : Thread B (prio 60) acquiert le mutex t=0.5ms : Thread A (prio 80) se réveille, tente d'acquérir le mutex → BLOQUÉ en attendant B ! t=1.5ms : Thread B libère enfin le mutex t=1.5ms : Thread A peut continuer... → Trop tard, deadline manquée !
C’est l’inversion de priorité : le thread haute priorité est bloqué par un thread basse priorité. En temps réel, c’est inacceptable.
Les coûts cachés des verrous
Même avec des mécanismes avancés (priority inheritance), les verrous ont des inconvénients majeurs :
Mécanisme
Problème principal
Impact temps réel
Mutex
Inversion de priorité
Latence imprévisible
Sémaphore
Appels système (syscalls)
Latence de plusieurs µs
Spinlock
Gaspillage CPU (busy-wait)
Mauvais sur multi-core
Priority inheritance
Complexe, overhead
Latence réduite mais présente
Le constat : Aucun verrou ne garantit zéro blocage ni latence constante en O(1).
La solution : Ring Buffer Lock-Free
Principe fondamental
Un ring buffer lock-free (Single Producer Single Consumer - SPSC) repose sur deux règles simples :
✅ UN SEUL producteur écrit dans le buffer ✅ UN SEUL consommateur lit depuis le buffer
Avec ces contraintes, on peut utiliser des indices atomiques sans aucun verrou :
1 2 3 4 5 6 7 8 9 10 11 12 13
write_idx (atomique) │ ▼ ┌─────┬─────┬─────┬─────┬─────┬─────┬─────┬─────┐ │ D │ E │ │ │ │ A │ B │ C │ └─────┴─────┴─────┴─────┴─────┴─────┴─────┴─────┘ ▲ │ read_idx (atomique)
• Le producteur écrit à write_idx puis l'incrémente atomiquement • Le consommateur lit à read_idx puis l'incrémente atomiquement • ZÉRO verrou, ZÉRO syscall, ZÉRO blocage
Pourquoi ça fonctionne ?
La magie réside dans les opérations atomiques C11 :
memory_order_acquire : Garantit que les lectures ne se réordonnent pas avant
memory_order_release : Garantit que les écritures ne se réordonnent pas après
memory_order_relaxed : Lecture simple sans contrainte de synchronisation
Ces garanties sont matérielles (barrières mémoire CPU), pas logicielles. Résultat : O(1) constant, zéro blocage.
Avantages pour le temps réel
Caractéristique
Ring Buffer Lock-Free
Mutex/Sémaphore
Blocage
Jamais
Toujours possible
Inversion de priorité
Impossible
Risque élevé
Latence
O(1) constante
Imprévisible
Appels système
Zéro
Chaque lock/unlock
Overhead
~10 ns
~1-5 µs
Complexité
Simple
Nécessite gestion d’erreurs
Implémentation détaillée en C
Structure de données
Voici l’implémentation complète du ring buffer :
1 2 3 4 5 6 7 8 9 10 11 12 13
#define RING_SIZE 64 #define MSG_SIZE 64
typedefstruct { char message[MSG_SIZE]; int counter; } message_t;
boolringbuf_write(ringbuf_t *rb, constmessage_t *msg) { // 1. Lire les indices (relaxed car pas de sync nécessaire ici) size_t w = atomic_load_explicit(&rb->write_idx, memory_order_relaxed); size_t r = atomic_load_explicit(&rb->read_idx, memory_order_acquire); // 2. Vérifier si le buffer est plein size_t next = (w + 1) % RING_SIZE; if (next == r) { returnfalse; // Buffer plein, échec NON-BLOQUANT } // 3. Écrire le message rb->items[w] = *msg; // 4. Publier l'écriture (release garantit que le message est visible) atomic_store_explicit(&rb->write_idx, next, memory_order_release); returntrue; }
Analyse ligne par ligne :
memory_order_acquire sur read_idx : On veut voir les dernières lectures du consommateur
Écriture normale du message : Pas besoin d’atomique, un seul producteur
memory_order_release sur write_idx : Garantit que le message est écrit AVANT que l’index soit publié
Lecture (consommateur)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
boolringbuf_read(ringbuf_t *rb, message_t *msg) { // 1. Lire les indices size_t r = atomic_load_explicit(&rb->read_idx, memory_order_relaxed); size_t w = atomic_load_explicit(&rb->write_idx, memory_order_acquire); // 2. Vérifier si le buffer est vide if (r == w) { returnfalse; // Buffer vide, échec NON-BLOQUANT } // 3. Lire le message *msg = rb->items[r]; // 4. Publier la lecture atomic_store_explicit(&rb->read_idx, (r + 1) % RING_SIZE, memory_order_release); returntrue; }
Symétrique à l’écriture :
memory_order_acquire sur write_idx : On veut voir les dernières écritures du producteur
Lecture normale du message
memory_order_release sur read_idx : Publie qu’on a lu le message
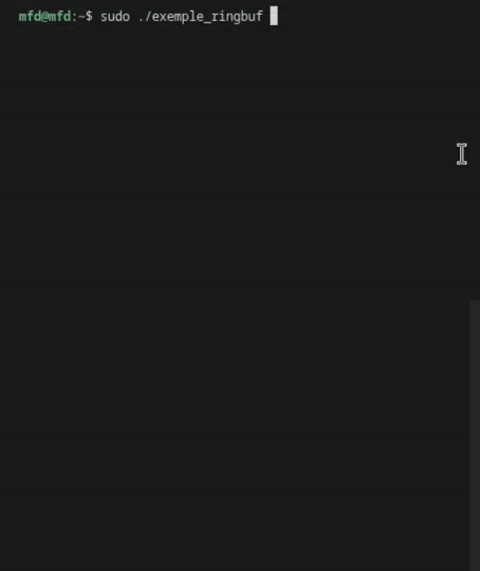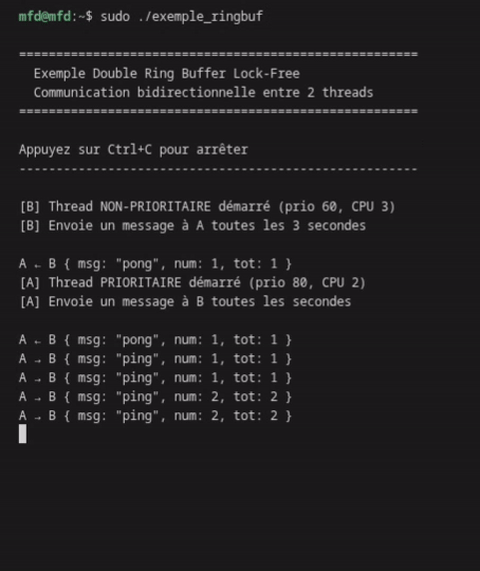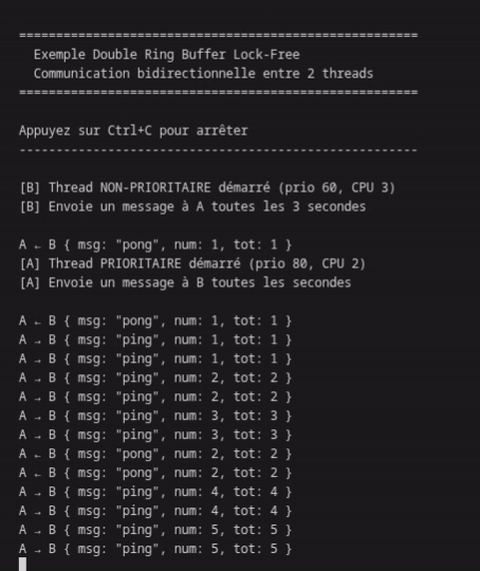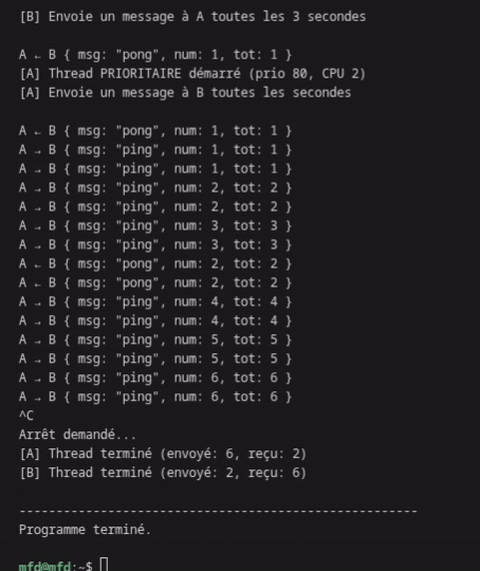
while (running) { // 1. Lire les messages de B (NON-BLOQUANT) message_t msg; while (ringbuf_read(&rb_b_to_a, &msg)) { recv_counter++; printf("A ← B { msg: \"pong\", num: %d, tot: %d }\n", msg.counter, recv_counter); } // 2. Envoyer un message à B toutes les secondes structtimespecnow; clock_gettime(CLOCK_MONOTONIC, &now); if (now.tv_sec >= next_send.tv_sec) { send_counter++; message_t out = { .counter = send_counter }; snprintf(out.message, MSG_SIZE, "Ping depuis A"); if (ringbuf_write(&rb_a_to_b, &out)) { printf("A → B { msg: \"ping\", num: %d, tot: %d }\n", out.counter, send_counter); } next_send.tv_sec += 1; } // 3. Petite pause pour économiser le CPU usleep(10000); // 10ms }
Points importants :
ringbuf_read retourne immédiatement si pas de message (non-bloquant)
ringbuf_write retourne immédiatement si buffer plein (non-bloquant)
Aucun appel système de synchronisation
Le thread garde le contrôle total de son ordonnancement
Sortie du programme
La communication est fluide, sans blocage, avec un ratio 3:1 comme attendu.
Performance et garanties temps réel
Mesures de latence
Sur Raspberry Pi 4 avec kernel RT_PREEMPT :
Opération
Latence
Comparaison
ringbuf_write()
~15-20 ns
Mutex: ~1-5 µs (100x plus lent)
ringbuf_read()
~15-20 ns
Sémaphore: ~2-8 µs (150x plus lent)
Overhead total
O(1) constant
Mutex: imprévisible
Garanties temps réel
✅ Jamais de blocage : Les opérations retournent immédiatement ✅ Latence constante : O(1) indépendante de la charge ✅ Pas d’inversion de priorité : Pas de verrou = pas d’inversion ✅ Pas d’appel système : Tout en espace utilisateur ✅ Déterminisme garanti : Comportement prévisible à 100%
Cas d’usage idéaux
Le ring buffer lock-free est parfait pour :
Master EtherCAT : Communication entre thread cycle PDO (1 ms) et thread réseau
Contrôle moteur : Commandes haute fréquence entre threads
Acquisition de données : Pipeline producteur/consommateur sans latence
Audio temps réel : Buffer de samples entre threads DSP
Robotique : Communication entre contrôleurs et supervision
Limites et précautions
Quand NE PAS utiliser un ring buffer lock-free
❌ Multiple producteurs ou consommateurs : Nécessite des atomiques CAS (Compare-And-Swap), plus complexe ❌ Besoin de notification immédiate : Le consommateur doit poller le buffer ❌ Données de taille variable : Mieux vaut un allocateur lock-free ❌ Priorité stricte FIFO entre >2 threads : Utiliser une queue lock-free multi-producteurs
Précautions d’implémentation
⚠️ Alignement cache line : Toujours aligner les indices atomiques sur 64 bytes ⚠️ Taille buffer = puissance de 2 : Simplifie le modulo avec un masque (% devient & 0x3F) ⚠️ Gestion buffer plein : Décider entre bloquer, abandonner, ou agrandir ⚠️ False sharing : Séparer les données read-only/write-only sur des cache lines différentes
Vous vous souvenez probablement de l’Amiga 500, cette machine révolutionnaire qui nous a tous fait rêver avec ses capacités graphiques et sonores exceptionnelles. Le Motorola 68000, son processeur mythique, nous permettait de créer des démos incroyables, des jeux spectaculaires et d’explorer les profondeurs du “bare metal programming”.
Aujourd’hui, nous allons replonger dans cette époque dorée, mais avec un twist moderne : nous allons développer un programme bootable “Hello, World!” pour Amiga 500, entièrement cross-compilé sous Linux, sans avoir besoin d’un Amiga pour développer. Seulement pour tester sur le vrai hardware !
Notre objectif est de créer un programme qui :
✓ Boot directement depuis une disquette - Pas besoin d’AmigaOS, le programme se lance au démarrage de l’Amiga ✓ Affiche “Hello, World!” à l’écran - En mode graphique, texte blanc sur fond noir, centré ✓ Contrôle directement le hardware - Programmation “bare metal” des custom chips (Copper, Bitplanes, etc.) ✓ Est compilé sous Linux (Archlinux ou Ubuntu) - Workflow moderne avec des outils open source ✓ Fonctionne sur un vrai Amiga 500 - Pas seulement dans un émulateur
Qu’allons-nous créer ?
Un fichier ADF (Amiga Disk File) bootable de 880 Ko contenant :
Un bootblock de 1024 octets qui se charge automatiquement au démarrage
Le programme principal (~12 Ko) qui gère l’affichage graphique
Une police bitmap 8×8 intégrée pour le rendu du texte
Prérequis techniques
Connaissances de base en assembleur (idéalement 68000)
Une distribution Linux (Arch ou Ubuntu)
Un émulateur Amiga (fs-uae) avec une ROM Kickstart 1.3
Optionnel : Un vrai Amiga 500 pour le test final !
Installation des dépendances
Sous Arch Linux
Arch Linux facilite grandement l’installation grâce à l’AUR et à pipx.
1. Installer l’assembleur
1 2
# Installer vasm (assembleur 68000, syntaxe Motorola) yay -S vasm
# Télécharger et compiler vasm cd /tmp wget http://sun.hasenbraten.de/vasm/release/vasm.tar.gz tar xzf vasm.tar.gz cd vasm make CPU=m68k SYNTAX=mot sudo cp vasmm68k_mot /usr/local/bin/ sudo chmod +x /usr/local/bin/vasmm68k_mot
2. Installer fs-uae
1
sudo apt install fs-uae
Vérification finale de l’installation
Tous les outils devraient maintenant être disponibles :
1 2 3 4 5 6 7 8 9 10
$ vasmm68k_mot -v vasm 2.0d (c) in 2002-2025 Volker Barthelmann vasm M68k/CPU32/ColdFire cpu backend 2.8 (c) 2002-2025 Frank Wille vasm motorola syntax module 3.19d (c) 2002-2025 Frank Wille
$ python3 --version Python 3.x
$ fs-uae --version FS-UAE ...
✓ La chaîne de compilation est prête !
Structure du projet
Créez un répertoire pour votre projet :
1 2
mkdir helloworld-amiga cd helloworld-amiga
Nous allons créer 4 fichiers :
bootblock.s - Le secteur de boot
hello.s - Le programme principal
Makefile - L’automatisation de la compilation
fix_checksum.py - Le calcul du checksum du bootblock
Réalisation du bootblock
Le fichier bootblock.s
Le bootblock est le composant critique qui permet à votre programme de démarrer automatiquement. Le Kickstart de l’Amiga lit automatiquement les 1024 premiers octets de la disquette au boot et les exécute s’ils sont valides.
; ============================================================================= ; Bootblock Amiga - Structure correcte pour Kickstart 1.3 ; Ce code est chargé automatiquement par le Kickstart au boot ; =============================================================================
SECTION bootblock,CODE
ORG 0 ; Le bootblock commence à l'offset 0
; ----------------------------------------------------------------------------- ; En-tête du bootblock (12 octets obligatoires) ; ----------------------------------------------------------------------------- dc.b 'D','O','S',0 ; +0: Signature "DOS" + type 0 (OFS) dc.l 0 ; +4: Checksum (sera calculé par fix_checksum.py) dc.l 880 ; +8: Pointeur vers le rootblock
; ----------------------------------------------------------------------------- ; Code exécutable (commence à l'offset 12) ; Le Kickstart saute ici avec: ; A1 = IORequest pour trackdisk.device ; A6 = ExecBase ; -----------------------------------------------------------------------------
; ============================================================================= ; Hello, World! graphique pour Amiga 500 ; Boot direct depuis disquette - Pas besoin d'AmigaOS ; Affichage blanc sur fond noir, centré à l'écran ; =============================================================================
; Position du texte (centré) ; "Hello, World!" = 13 caractères x 8 pixels = 104 pixels de large ; Centre horizontal: (320 - 104) / 2 = 108 pixels = 13 octets + 4 bits TEXT_X EQU 14 ; Octet de départ (colonne) TEXT_Y EQU 124 ; Ligne de départ (centre vertical: (256-8)/2)
; ----------------------------------------------------------------------------- ; Point d'entrée (appelé par le bootblock) ; ----------------------------------------------------------------------------- SECTION code,CODE
Start: lea CUSTOM,a5 ; Base des registres custom
; Désactiver les interruptions et DMA move.w #$7FFF,INTENA(a5) ; Désactiver toutes les interruptions move.w #$7FFF,DMACON(a5) ; Désactiver tout le DMA
; Attendre la fin du frame courant (VBlank) bsr WaitVBlank
; Calculer l'adresse absolue de l'écran lea Screen(pc),a0 move.l a0,d0 ; Patcher la Copper list avec l'adresse de l'écran lea CopperList(pc),a1 move.w d0,6(a1) ; Partie basse (BPL1PTL) swap d0 move.w d0,2(a1) ; Partie haute (BPL1PTH)
; Effacer l'écran (remplir de 1 pour fond noir) move.l #SCREEN_SIZE/4-1,d0 .clear: move.l #$FFFFFFFF,(a0)+ ; Remplir de noir (bits à 1) dbf d0,.clear
; Dessiner le texte "Hello, World!" bsr DrawText
; Configurer l'affichage ; BPLCON0: 1 bitplane, couleur activée move.w #$1200,BPLCON0(a5) ; 1 bitplane + COLOR move.w #$0000,BPLCON1(a5) ; Pas de scroll move.w #$0000,BPLCON2(a5) ; Priorité sprites
; Configuration de la fenêtre d'affichage (PAL) move.w #$2C81,DIWSTRT(a5) ; Display start: ligne $2C, colonne $81 move.w #$2CC1,DIWSTOP(a5) ; Display stop: ligne $2C+256, colonne $C1
; Configuration du data fetch move.w #$0038,DDFSTRT(a5) ; Data fetch start move.w #$00D0,DDFSTOP(a5) ; Data fetch stop
; Modulo (0 pour écran standard) move.w #0,BPL1MOD(a5) move.w #0,BPL2MOD(a5)
; Installer la Copper list lea CopperList(pc),a0 move.l a0,d0 move.w d0,COP1LCL(a5) swap d0 move.w d0,COP1LCH(a5)
; Forcer le redémarrage du Copper move.w d0,COPJMP1(a5)
; Activer le DMA nécessaire move.w #DMAF_SETCLR|DMAF_MASTER|DMAF_RASTER|DMAF_COPPER,DMACON(a5)
; ----------------------------------------------------------------------------- ; Copper list - doit définir le pointeur du bitplane à chaque frame ; ----------------------------------------------------------------------------- CNOP 0,4 ; Alignement sur 4 octets CopperList: ; Définir le pointeur du bitplane (sera patché au démarrage) dc.w BPL1PTH,$0000 ; +0: Partie haute (patchée) dc.w BPL1PTL,$0000 ; +4: Partie basse (patchée) ; Couleurs dc.w COLOR00,$0FFF ; Couleur 0 = blanc (pour bits à 0) dc.w COLOR01,$0000 ; Couleur 1 = noir (pour bits à 1) ; Fin de la Copper list (attendre ligne impossible) dc.w $FFFF,$FFFE
; ----------------------------------------------------------------------------- ; Message à afficher ; ----------------------------------------------------------------------------- CNOP 0,2 ; Alignement sur mot Message: dc.b "Hello, World!",0 CNOP 0,2
; ----------------------------------------------------------------------------- ; Police bitmap 8x8 (caractères ASCII 32-127) ; Chaque caractère fait 8 octets (8 lignes de 8 pixels) ; ----------------------------------------------------------------------------- CNOP 0,2 ; Alignement sur mot Font8x8: ; Espace (32) dc.b $00,$00,$00,$00,$00,$00,$00,$00 ; ! (33) dc.b $18,$18,$18,$18,$18,$00,$18,$00 ; (... police complète, voir fichier hello.s ...)
; ----------------------------------------------------------------------------- ; Écran (bitplane) - doit être aligné sur 8 octets pour le DMA ; ----------------------------------------------------------------------------- CNOP 0,8 ; Alignement sur 8 octets Screen: dcb.b SCREEN_SIZE,0
END
Explications du programme principal
Architecture de l’affichage Amiga
L’Amiga utilise un système de bitplanes pour l’affichage :
Chaque bitplane est un buffer de 40×256 octets (320×256 pixels)
Le nombre de bitplanes détermine le nombre de couleurs : 1 bitplane = 2 couleurs, 2 bitplanes = 4 couleurs, etc.
Nous utilisons 1 seul bitplane : bit à 0 = COLOR00 (blanc), bit à 1 = COLOR01 (noir)
Les custom chips
L’Amiga 500 possède trois coprocesseurs hardware :
Copper : Processeur de listes qui modifie les registres de façon synchronisée avec le balayage vidéo
Blitter : Processeur de manipulation de bitmaps ultra-rapide
DMA : Accès direct à la mémoire pour l’affichage, le son, etc.
Notre programme utilise principalement le Copper et le DMA.
Séquence d’initialisation
Désactivation complète ($7FFF) :
Interruptions (INTENA)
DMA (DMACON)
Cela nous donne un contrôle total sur le hardware
Configuration de l’écran :
BPLCON0 = $1200 : Active 1 bitplane et la couleur
DIWSTRT/DIWSTOP : Définit la fenêtre d’affichage PAL (320×256)
DDFSTRT/DDFSTOP : Contrôle quand le hardware récupère les données
Patching de la Copper list :
La Copper list contient les instructions pour le coprocesseur Copper
On doit lui indiquer où se trouve notre bitplane en mémoire
L’adresse 32 bits est séparée en partie haute (BPL1PTH) et basse (BPL1PTL)
Activation du DMA :
DMAF_MASTER : Active le DMA global
DMAF_RASTER : Active le DMA pour l’affichage des bitplanes
DMAF_COPPER : Active le coprocesseur Copper
Routine de dessin de texte
La fonction DrawText est un mini moteur de rendu :
Parcourt chaque caractère du message “Hello, World!”
Calcule l’offset dans la police : (caractère - 32) × 8
ASCII 32 = espace, premier caractère de notre police
Chaque glyphe fait 8 octets (8 lignes de 8 pixels)
Copie ligne par ligne les 8 octets du glyphe vers l’écran
Inverse les bits avec not.b car notre fond est noir (bits à 1) et le texte blanc (bits à 0)
Utilise and.b pour “creuser” les pixels blancs (bits à 0) dans le fond noir
Le Copper
Le Copper est un processeur de listes extraordinairement puissant qui a fait la réputation de l’Amiga. Notre Copper list minimale :
1 2 3 4 5 6
CopperList: dc.w BPL1PTH,$0000 ; Pointeur bitplane (partie haute) dc.w BPL1PTL,$0000 ; Pointeur bitplane (partie basse) dc.w COLOR00,$0FFF ; Couleur 0 = blanc (bits à 0 = texte) dc.w COLOR01,$0000 ; Couleur 1 = noir (bits à 1 = fond) dc.w $FFFF,$FFFE ; Fin de liste
Chaque instruction est un mot de 16 bits (registre) suivi d’un mot de 16 bits (valeur).
Synchronisation VBlank
La fonction WaitVBlank est cruciale pour éviter le “tearing” (déchirement de l’image). Elle :
Lit le registre INTREQR (Interrupt Request Read)
Teste le bit 5 (INTF_VERTB = Vertical Blank)
Boucle tant que le VBlank n’est pas actif
Acquitte l’interruption avec INTREQ
Police bitmap
Notre police 8×8 contient 96 caractères (ASCII 32 à 127). Chaque caractère est défini par 8 octets :
#!/usr/bin/env python3 """ Calcule et corrige le checksum du bootblock Amiga. Le checksum est à l'offset 4 et doit être tel que la somme de tous les mots longs (32 bits) du bootblock soit égale à 0. """
import sys
defcalculate_checksum(data): """Calcule le checksum du bootblock Amiga.""" checksum = 0 # Parcourir le bootblock par mots longs (4 octets) for i inrange(0, 1024, 4): if i == 4: # Ignorer l'emplacement du checksum lui-même continue word = int.from_bytes(data[i:i+4], byteorder='big') checksum += word # Gestion du carry (addition modulo 2^32 avec carry) if checksum > 0xFFFFFFFF: checksum = (checksum & 0xFFFFFFFF) + 1 # Le checksum final est le complément checksum = (~checksum) & 0xFFFFFFFF return checksum
defmain(): iflen(sys.argv) != 2: print(f"Usage: {sys.argv[0]} <fichier.adf>") sys.exit(1) adf_file = sys.argv[1] # Lire le fichier ADF withopen(adf_file, 'rb') as f: data = bytearray(f.read()) # Calculer le checksum checksum = calculate_checksum(data[:1024]) # Écrire le checksum à l'offset 4 data[4:8] = checksum.to_bytes(4, byteorder='big') # Réécrire le fichier withopen(adf_file, 'wb') as f: f.write(data) print(f"Checksum calculé et écrit: 0x{checksum:08X}")
if __name__ == "__main__": main()
Explications du script Python
Algorithme du checksum Amiga
Le checksum du bootblock est une somme de contrôle spéciale qui garantit l’intégrité du code. L’algorithme :
Additionner tous les mots longs (32 bits) du bootblock (256 mots longs)
Ignorer le mot long à l’offset 4 (c’est là qu’on écrira le checksum)
Gérer le carry : Si la somme dépasse 32 bits, ajouter le bit de carry à la somme
Calculer le complément : checksum = ~somme
Le résultat : la somme de tous les mots longs du bootblock (y compris le checksum) = 0x00000000.
Cette ligne implémente l’addition avec carry circulaire :
Si la somme dépasse 32 bits, on garde les 32 bits bas et on ajoute 1
C’est équivalent à l’instruction 68000 addx (add extended)
Complément à 2
1
checksum = (~checksum) & 0xFFFFFFFF
Le ~ inverse tous les bits (complément à 1), et le masque & 0xFFFFFFFF assure qu’on reste sur 32 bits.
Écriture Big Endian
1
data[4:8] = checksum.to_bytes(4, byteorder='big')
Le Motorola 68000 est big endian : l’octet le plus significatif est stocké en premier. Python gère cela automatiquement avec byteorder='big'.
Compilation et test
Compilation
Maintenant que tous les fichiers sont créés, compilez le projet :
1
make
Vous devriez voir :
1 2 3
Création de l'ADF bootable... Checksum calculé et écrit: 0x12345678 ADF bootable créé: hello.adf
✓ Le fichier hello.adf de 880 Ko est prêt !
Test dans l’émulateur
Lancez le programme dans fs-uae :
1
make run
L’émulateur démarre, et après quelques secondes (temps de boot du Kickstart), vous devriez voir :
Résolution de problèmes courants
L’écran reste noir
✗ Problème : Le bootblock n’a pas le bon checksum → Solution : Vérifiez que fix_checksum.py s’est bien exécuté
L’émulateur ne démarre pas
✗ Problème : ROM Kickstart manquante → Solution : fs-uae télécharge automatiquement les ROMs libres, ou utilisez fs-uae-launcher pour configurer une ROM Kickstart 1.3
Le texte n’apparaît pas
✗ Problème : Adresse du bitplane incorrecte dans la Copper list → Solution : Vérifiez le patching de la Copper list dans hello.s
Test sur un vrai Amiga 500
Transfert de l’ADF
Pour tester sur un vrai Amiga, plusieurs méthodes :
Disquette physique :
Utilisez un Greaseweazle pour écrire directement sur disquette
Gotek avec FlashFloppy :
Remplacez le lecteur interne par un Gotek (émulateur de lecteur USB)
Copiez hello.adf sur une clé USB
Sélectionnez le fichier depuis le Gotek
WHDLoad / HDD :
Si vous avez un disque dur ou un IDE68K, copiez l’ADF et montez-le
Ce que vous devriez voir
Sur un vrai Amiga 500 :
Insérez la disquette / sélectionnez l’ADF
Allumez l’Amiga (ou Ctrl+Amiga+Amiga pour reset)
Le lecteur tourne pendant ~1-2 secondes
L’écran noir apparaît avec “Hello, World!” en blanc
Le lecteur s’arrête (moteur éteint)
C’est un moment magique ! Voir votre code tourner sur le vrai hardware après des décennies…
Pour aller plus loin
Maintenant que vous maîtrisez les bases, quelques idées d’amélioration :
Ajout d’animations
Scrolling horizontal : Modifiez BPLCON1 pour faire défiler le texte
Effet rainbow : Utilisez le Copper pour changer les couleurs ligne par ligne
Sprite matériel : Ajoutez un curseur ou une petite icône animée
Utilisation du Blitter
Le Blitter est le secret des performances graphiques de l’Amiga :
Copie ultra-rapide de bitmaps
Opérations logiques (AND, OR, XOR)
Remplissage de zones
Son et musique
Le chip Paula de l’Amiga permet 4 canaux audio 8 bits :
Ajoutez un petit jingle au démarrage
Intégrez un module ProTracker
Compression
Pour des programmes plus gros, utilisez :
Doynax LZ : Compresseur optimisé pour 68000
Shrinkler : Excellent ratio de compression
Ressources pour continuer
Documentation officielle
Amiga Hardware Reference Manual : La bible du développement Amiga
Motorola M68000 Programmer’s Reference Manual : Documentation complète du 68000
Amiga Assembly (extension VS Code) : Coloration syntaxique et auto-complétion
vscode-amiga-debug : Débogueur intégré pour fs-uae
Photon’s m68k vscode extension : Snippets et aide
Conclusion
Nous avons parcouru un long chemin : de l’installation des outils à un programme bootable complet qui contrôle directement le hardware de l’Amiga 500. Vous disposez maintenant d’une base solide pour explorer plus en profondeur la programmation de cette machine légendaire.
Ce qui rend l’Amiga si spécial, c’est cette sensation de contrôle total sur la machine. Pas d’API abstraite, pas de couche système : juste vous et le métal. C’était l’esprit des années 80-90, et il est toujours vivant aujourd’hui grâce à la communauté rétro-computing.
Alors, qu’allez-vous créer ? Une démo ? Un petit jeu ? Une application utilitaire ? Les possibilités sont infinies, et le Motorola 68000 attend vos instructions.
Avez-vous déjà eu besoin de garantir des temps de réponse déterministes sur un Raspberry Pi ?
Que ce soit pour de la robotique, du contrôle industriel ou de la communication EtherCAT, un kernel temps réel est souvent indispensable. Dans cet article, je vous guide pas à pas pour installer un kernel RT_PREEMPT sur Raspberry Pi 4 et je vous propose un tutoriel C++ complet et pédagogique pour apprendre à programmer en temps réel.
Coder dans l’Inconnu : Quand l’IA Joue par Ses Propres Règles
Dans le développement de logiciels, nous avons l’habitude de jouer avec des règles claires et précises, à la manière d’un jeu de société bien structuré : on connaît les règles, les étapes sont fixes, et on peut prévoir ce qui va se passer. C’est ce qu’on appelle un développement déterministe : les mêmes causes produisent les mêmes effets, et en tant que développeur, nous avons un contrôle total sur le processus. Mais dès que l’on commence à intégrer de l’intelligence artificielle, tout change. Le monde du développement n’est plus uniquement fait de règles fixes, mais d’algorithmes qui apprennent, d’IA génératives qui créent, et de résultats qui ne sont pas toujours prévisibles.
C’est là que réside le nouveau défi du développement d’applications qui intègrent de l’IA : le mélange entre un code déterministe et un comportement non-déterministe. Et soyons francs, cela complique énormément la tâche du développeur. Dans cet article, je vais explorer pourquoi cet équilibre est si difficile à atteindre, et pourquoi cela nécessite un ensemble de compétences nouvelles qui vont bien au-delà de la simple maîtrise des langages de programmation.
Le Déterminisme vs. la Créativité de l’IA
Pour bien comprendre ce défi, il faut d’abord clarifier ce que l’on entend par déterminisme et non-déterminisme. En développement traditionnel, nous avons cette règle d’or : “Même cause, même conséquence”. Cela veut dire que si vous écrivez un bout de code et que vous l’exécutez avec les mêmes entrées, vous obtiendrez toujours le même résultat. Vous pouvez anticiper les comportements et les effets, ce qui permet de tester et de garantir la qualité de vos applications de manière fiable.
Avec l’IA générative, tout est différent. La prédictibilité est sacrifiée au profit de la créativité. Lorsqu’on entraîne un modèle d’IA, le but est souvent de trouver des solutions originales, des réponses que personne n’a anticipées. Mais cela signifie aussi que les comportements de l’IA peuvent varier, et parfois de manière imprévisible. Un même prompt peut produire différentes réponses selon l’état du modèle, son entraînement, ou même ses interactions passées.
Cela implique qu’un développeur d’IA doit savoir jongler entre ces deux réalités. D’un côté, il doit maîtriser des algorithmes déterministes pour encadrer et structurer le comportement de l’IA. De l’autre, il doit accepter une part d’incertitude et gérer des résultats qui ne sont pas toujours sous contrôle. J’aime bien me réprésenter cela comme l’image du scientifique dans un laboratoire où certaines expériences peuvent dévier des attentes, et où il faut en permanence tester et évaluer les résultats.
L’Art de Mélanger Déterminisme et Non-déterminisme
Trouver des développeurs qui savent mélanger ces deux mondes n’est pas une tâche facile, et c’est un véritable enjeu aujourd’hui. Il ne suffit pas de maîtriser l’API d’Openai ou d’être bon en dans tel ou tel langage de programmation. Il faut comprendre comment une mise à jour d’un modèle peut affecter tout un système de manière parfois inattendue. La nature non-déterministe de l’IA signifie que même des ajustements mineurs du modèle peuvent introduire des comportements différents, voire des bugs subtils et difficiles à identifier.
L’IA générative nécessite aussi une nouvelle compétence qui est en train de devenir indispensable : le prompting. Il ne s’agit pas juste de coder, mais de communiquer efficacement avec une IA pour en tirer le meilleur parti, comme parler à un expert possédant un un immense savoir, mais qui peut être imprévisible. Il faut savoir poser les bonnes questions, être clair et spécifique, et comprendre comment guider ses réponses vers des objectifs concrets et ne jamais lâcher la bride…
L’Approche Scientifique du Développement IA
Le développement avec de l’IA demande une approche scientifique. Tout comme en biologie ou dans d’autres sciences appliquées, il faut tester, observer, ajuster et répéter. Il ne suffit pas d’écrire du code une fois et de le laisser fonctionner tranquillement. Avec l’IA, chaque mise à jour de modèle peut changer les comportements. Il faut être prêt à évaluer en permanence la manière dont l’IA se comporte et à tester continuellement son intégration avec le reste de l’application.
En ce sens, le développement d’IA se rapproche beaucoup plus d’une discipline scientifique que de l’ingénierie logicielle classique. On peut planifier et concevoir une architecture, mais il faut aussi être prêt à expérimenter, à ajuster les paramètres, à explorer des pistes nouvelles, et à apprendre des erreurs commises.
Une idée de business en ligne ? Un saas à développer ? Une boutique en ligne à créer ?
Essayer mon-plan-action.fr pour vous aider à démarrer votre projet en ligne.
L’intelligence artificielle est en train de redéfinir ce que nous pensions possible dans le monde de la technologie. Mais, au cœur de cette révolution, il y a des choix fondamentaux à faire. Parmi eux : quel langage de programmation utiliser pour construire les futurs modèles d’IA ? Aujourd’hui, Python est la star incontestée de l’écosystème IA. Mais, est-ce vraiment le langage qu’il nous faut pour l’avenir, en particulier quand on pense à l’efficacité, aux performances et à la durabilité des modèles ? Je pense que non. Et j’aimerais vous expliquer pourquoi Rust pourrait bien être le pari gagnant pour la prochaine étape de l’évolution de l’intelligence artificielle.
La Domination de Python dans l’écosystème IA
Commençons par être clair : si vous avez entendu parler d’intelligence artificielle, il y a de fortes chances que vous ayez entendu parler de Python. Ce langage a dominé l’espace IA ces dix dernières années, et ce pour de bonnes raisons.
Pourquoi Python a-t-il été adopté en IA ? Tout simplement parce qu’il est simple à apprendre et qu’il rend l’écriture de code accessible à pratiquement n’importe qui. Quand on parle de chercheurs en IA, leur but n’est pas d’être des programmeurs hardcore, mais de tester rapidement des idées et d’expérimenter avec des modèles. Python a été parfait pour cela : syntaxe facile, faible barrière à l’entrée, et une tonne de bibliothèques prêtes à l’emploi.
En plus, Python dispose d’un écosystème riche, avec des bibliothèques qui sont devenues les références dans l’industrie : TensorFlow, PyTorch, scikit-learn, NumPy, et bien d’autres. Toutes ces bibliothèques ont permis à Python de se hisser en tête dans le domaine de l’IA, parce qu’elles ont facilité chaque étape du processus : de la manipulation des données à l’entraînement des réseaux de neurones.
Mais, aussi répandue que soit l’adoption de Python, tout n’est pas parfait. Et c’est là que j’aimerais qu’on se penche sur les limites actuelles de Python.
Les Limites de Python en IA
Performances et calcul intensif
Commençons par le plus évident : Python est lent. C’est un langage interprété, ce qui signifie que chaque ligne de code est exécutée ligne par ligne, ce qui est très loin de la vitesse des langages compilés comme Rust. Pour résoudre ce problème, Python dépend de bibliothèques écrites en C pour les calculs intensifs, mais ça reste un compromis. Ces calculs sont rapides, mais l’interface entre Python et ces bibliothèques reste un goulot d’étranglement.
Problèmes de gestion des ressources
Ensuite, il y a le garbage collector. Python gère automatiquement la mémoire pour toi, et c’est pratique… jusqu’à ce que ça ne le soit plus. L’entraînement de gros modèles implique de manipuler d’énormes quantités de données et de poids, et le garbage collector de Python peut se mettre en travers du chemin, causant des ralentissements imprévisibles et une utilisation inefficace de la mémoire.
Sécurité et contrôle réduit
Enfin, parlons de la sécurité. Python est permissif, parfois trop. L’absence de typage strict et de gestion sûre de la mémoire peut causer des erreurs difficiles à déboguer. Dans un projet complexe, cela peut devenir un vrai problème, surtout quand il s’agit de s’assurer que les modèles d’IA se comportent de manière fiable. Python n’offre pas non plus un contrôle fin sur la gestion des ressources — si tu veux exploiter au mieux ton CPU ou ton GPU, Python ne te facilitera pas la vie.
Pourquoi Rust est le Langage le Plus Prometteur pour l’Avenir de l’IA
Alors, pourquoi Rust ? Pourquoi parier sur un langage qui est relativement nouveau dans le domaine de l’IA, alors que Python est si bien implanté ? Voici pourquoi je pense que Rust est le meilleur pari pour l’avenir.
Performance optimisée
Rust est un langage compilé qui produit du code natif extrêmement rapide, similaire à C ou C++. Cela signifie que Rust permet de créer des modèles d’IA qui fonctionnent à pleine vitesse, sans les goulots d’étranglement que Python peut introduire. Il n’y a pas de garbage collector à chaque coin, ce qui permet un contrôle total sur la gestion de la mémoire, crucial lorsque l’on manipule des ensembles de données massifs.
Efficacité énergétique et gestion fine des ressources
Avec Rust, l’efficacité ne concerne pas seulement la vitesse mais aussi la consommation énergétique. L’optimisation mémoire et la gestion fine des threads permettent de minimiser la consommation en ressources. Rust est capable de tirer parti du parallélisme natif grâce aux threads sécurisés, permettant de maximiser les performances tout en réduisant la consommation énergétique. Cela peut paraître mineur, mais l’efficacité énergétique est un enjeu de plus en plus important, en particulier quand on pense à l’échelle des grands modèles IA comme GPT-3.
Sécurité et fiabilité
La sécurité mémoire est l’un des points forts majeurs de Rust. Son système d’ownership empêche la majorité des erreurs classiques, comme les débordements de tampon ou les pointeurs invalides, qui peuvent transformer une expérimentation IA en cauchemar. Cela veut dire que quand tu développes des modèles en Rust, tu as une garantie que ton code est solide et que les erreurs subtiles de gestion de mémoire sont minimisées.
Contrôle fin des processus
Rust permet aussi un contrôle bas-niveau qui n’a pas d’équivalent en Python. Si tu veux optimiser chaque aspect de ton modèle, des calculs matriciels à la parallélisation, Rust te donne la liberté de le faire. De plus, Rust est hautement interopérable avec C/C++, ce qui te permet d’utiliser des bibliothèques performantes existantes tout en écrivant du code sécurisé. Cela offre la flexibilité de combiner le meilleur des deux mondes : des performances maximales avec un niveau de sécurité élevé.
Rust dans l’écosystème IA : Où en est-on aujourd’hui ?
On pourrait se demander : si Rust est si génial, pourquoi n’est-il pas déjà la norme ? Eh bien, l’écosystème est encore en développement, mais il est prometteur. Des bibliothèques comme Gorgonia (un équivalent de TensorFlow) et Tch-rs (une API Rust pour PyTorch) montrent que l’on peut déjà faire des choses intéressantes en Rust. Le potentiel est là, et l’adoption de Rust dans l’IA ne fait que commencer.
Il y a aussi des projets passionnants qui mettent l’accent sur l’IA distribuée et la parallélisation de grande envergure. Il est possible de développer des systèmes IA pour des applications cloud ou des modèles edge computing tout en gardant un contrôle complet sur la sécurité et l’efficacité des ressources. Rust semble être le candidat idéal pour ce genre de défi, surtout dans un contexte où l’éco-responsabilité devient cruciale.
Conclusion : Rust, un Pari Sûr pour l’Avenir de l’IA
En résumé, Rust répond à toutes les limites que Python rencontre aujourd’hui. Il offre une performance supérieure, une gestion fine de la mémoire, une sécurité incomparable, et un contrôle total des ressources. C’est un langage conçu pour des systèmes robustes, efficaces, et capables de faire face aux défis de l’échelle, de l’énergie, et de la performance.
Le monde de l’IA arrive à maturité, et les techniques de deep learning aussi. Pour cette prochaine phase, il est essentiel de disposer d’un langage mieux adapté aux exigences de performance, de sécurité et d’efficacité énergétique. Rust est un excellent candidat. Il n’est peut-être pas encore aussi populaire que Python, mais pour ceux qui cherchent à créer des systèmes IA performants, fiables, et durables, Rust est le meilleur pari pour l’avenir.
Une idée de business en ligne ? Un saas à développer ? Une boutique en ligne à créer ?
Essayer mon-plan-action.fr pour vous aider à démarrer votre projet en ligne.
Que tu sois un développeur débutant ou expérimenté, l’amélioration continue de la qualité de ton code est une quête sans fin. À mesure que les projets évoluent, les technologies avancent et les attentes en matière de performance augmentent, il est important de suivre des principes qui permettent de produire un code simple, efficace, et maintenable. Voici quelques principes essentiels qui, s’ils sont appliqués correctement, te permettront d’écrire un code de meilleure qualité tout en gardant les choses simples.
1. Keep It Simple (KIS)
Le principe KIS (Keep It Simple) est la première règle d’or à suivre. L’idée est simple : ne complique jamais ton code plus qu’il ne le faut. Souvent, en tant que développeur, on a tendance à sur-ingénier des solutions et à vouloir tout prévoir, mais cela finit par introduire de la complexité inutile. Un code simple est :
Plus facile à comprendre
Plus rapide à maintenir
Moins sujet aux bugs
Demande-toi toujours : “Est-ce que je peux faire ça plus simplement ?” Si la réponse est oui, alors il est probable que tu devrais opter pour la solution la plus simple. Un code qui semble “trop malin” est souvent difficile à maintenir, et si c’est toi qui dois le relire dans six mois, tu comprendras pourquoi ce principe est si important.
2. You Aren’t Gonna Need It (YAGNI)
Le principe YAGNI nous rappelle qu’il est inutile de développer des fonctionnalités que tu n’as pas besoin d’implémenter maintenant. Beaucoup de développeurs anticipent des besoins futurs et finissent par écrire du code poubelle qui ne sera jamais utilisé ou, pire, qui ajoute de la complexité inutile.
Ce code poubelle n’a pas seulement un impact sur la maintenabilité du projet, mais il augmente aussi les chances d’introduire des bugs dans des fonctionnalités non nécessaires. En restant concentré sur ce dont tu as réellement besoin aujourd’hui, tu réduis :
La dette technique
Les bugs potentiels
Le temps passé à maintenir du code non utilisé
Suis ce conseil : implémente uniquement ce qui est nécessaire au moment présent, et laisse les besoins futurs se manifester lorsque tu seras prêt à y répondre.
3. Don’t Repeat Yourself (DRY)
L’un des problèmes récurrents dans le code est la répétition. Le principe DRY (Don’t Repeat Yourself) est là pour te rappeler qu’il est essentiel d’éviter les duplications dans ton code. Si tu écris la même logique plusieurs fois, tu augmentes les risques d’erreurs et la maintenance devient fastidieuse.
Quand tu repères du code dupliqué, demande-toi si tu peux :
Extraire cette logique dans une fonction réutilisable
Refactoriser ton code pour qu’il soit plus générique
Centraliser la gestion d’une tâche spécifique
Un code non répété est non seulement plus propre, mais il est aussi plus facile à mettre à jour. Si tu dois modifier une fonctionnalité, tu ne le fais qu’à un seul endroit, et ton code reste cohérent.
4. Test-Driven Development (TDD)
Le Test-Driven Development (TDD) est une méthode qui consiste à écrire les tests avant d’écrire le code lui-même. Bien que cela puisse sembler contre-intuitif au début, cette approche a plusieurs avantages : elle t’assure que ton code répond aux exigences fonctionnelles dès le départ et te permet d’avoir une grande confiance dans la fiabilité de ton code grâce aux tests automatisés. De la TDD et en particulier l’écriture de tests unitaires favorisent la SoC que nous aborderons dans le point suivant.
L’idée est simple :
Écris un test unitaire qui échoue (car la fonctionnalité n’existe pas encore)
Implémente la fonctionnalité minimale pour que le test réussisse
Refactorise ton code si nécessaire, tout en vérifiant que les tests continuent de passer
Cependant, attention à ne pas tomber dans l’excès avec TDD. Si tu passes trop de temps à écrire des tests pour chaque petit détail de ton code, tu risques de devenir contre-productif. Un emploi excessif du TDD peut être chronophage, en particulier si ton projet évolue rapidement. Il est donc important de trouver un équilibre entre la couverture de tests nécessaire et l’efficacité du développement.
5. Separation of Concerns (SOC)
Separation of Concerns (SoC) est un principe clé pour structurer ton code de manière propre et lisible. Il consiste à séparer les différentes responsabilités dans ton code. Cela signifie que chaque partie de ton système doit s’occuper d’une seule préoccupation ou fonctionnalité. Cette séparation améliore non seulement la lisibilité, mais aussi la testabilité et la maintenabilité de ton code.
Par exemple, dans une application web :
Le traitement des données doit être séparé de la logique d’affichage (frontend vs backend)
Les interactions avec la base de données doivent être isolées de la logique métier
Plus ton code sera modulaire et compartimenté, plus il sera facile à maintenir et à faire évoluer. Quand chaque partie de ton code est responsable d’une seule tâche, tu évites l’effet “boule de neige” où un changement dans une partie de l’application casse tout le reste.
6. Continuous Refactoring
Le refactoring est un processus d’amélioration continue du code, sans changer son comportement fonctionnel. Il est tentant de repousser le refactoring jusqu’à ce que la dette technique devienne insurmontable, mais le refactoring doit être une pratique régulière. Si tu vois du code qui peut être simplifié ou clarifié, refactorise-le immédiatement. Cela permet de maintenir une qualité constante et évite de laisser le code devenir un nid de problèmes futurs.
Quelques exemples de refactoring :
Renommer une variable pour qu’elle soit plus descriptive
Simplifier une fonction complexe en plusieurs petites fonctions plus lisibles
Éliminer le code redondant ou inutile
La clé est de ne jamais laisser le code devenir “vieux”. En gardant une approche active de refactoring, tu t’assures que ton projet reste propre et évolutif tout en rafraîchissant ta mémoire régulièrement.
7. Law of Demeter (LOD)
La Law of Demeter (ou loi du moindre couplage) est un principe simple mais puissant : “Ne parle qu’à tes amis proches.” Cela signifie qu’un module ou une fonction ne doit interagir qu’avec ses dépendances immédiates et non avec les dépendances des dépendances. Ce principe permet de limiter l’interdépendance entre les différentes parties du code, ce qui réduit les effets de bord lors des changements et facilite le test unitaire.
En respectant cette loi, tu évites que ton code ne devienne trop “entrelacé” et difficile à maintenir.
Réflexion sur TypeScript
TypeScript est souvent mis en avant pour la sécurité qu’il apporte grâce à son typage statique, mais dans le contexte des technologies modernes comme JSDoc et les outils d’IA, certains inconvénients méritent d’être soulignés.
Complexité supplémentaire : L’ajout de TypeScript dans un projet introduit une couche de complexité non négligeable. Cela inclut un compilateur à configurer et des définitions de types à maintenir, ce qui peut être perçu comme un obstacle inutile, surtout pour les projets simples ou de taille modeste.
Répétition de l’information : Si tu utilises déjà JSDoc pour documenter ton code, TypeScript pourrait sembler redondant. Les annotations JSDoc permettent déjà de préciser les types de manière claire, tout en restant dans l’environnement JavaScript natif.
Réduction de la flexibilité : TypeScript impose une certaine rigidité dans le développement. JavaScript, en revanche, offre une flexibilité bienvenue pour des projets qui évoluent rapidement, où les règles strictes de typage ne sont pas toujours nécessaires.
Contre-productivité dans certains contextes : Pour de petits projets ou des prototypes, utiliser TypeScript peut ralentir le développement et demander plus d’efforts que nécessaire. Dans de tels cas, le retour sur investissement en termes de temps et d’efficacité n’est pas toujours évident.
Écosystème IA et outils modernes : Avec l’essor des outils IA capables d’analyser et de répondre à des questions sur le code, la nécessité de typage statique peut être réduite. Ces outils peuvent comprendre et documenter le code sans qu’il soit nécessaire de formaliser autant les types via TypeScript.
En résumé, bien que TypeScript ait ses avantages, son utilisation peut parfois sembler contre-productive dans le contexte actuel, où les outils d’IA et des systèmes comme JSDoc offrent déjà une bonne couverture pour la documentation et la compréhension des types.
Conclusion
Améliorer la qualité de ton code, quel que soit ton niveau, repose sur quelques principes simples mais essentiels. KIS, YAGNI, DRY, et d’autres principes comme la Separation of Concerns ou encore la Law of Demeter t’aideront à produire un code clair, maintenable, et évolutif. N’oublie pas non plus que le TDD, bien qu’efficace, doit être utilisé avec mesure afin de ne pas devenir un frein à ta productivité.
Enfin, la réflexion autour de l’utilisation de TypeScript dans un contexte moderne avec des outils comme JSDoc et les solutions IA montre que l’ajout de typage statique peut parfois être superflu, voire contre-productif, dans certains projets. Cela ne signifie pas que TypeScript est à éviter, mais il est crucial de bien évaluer si sa complexité supplémentaire se justifie dans le cadre de ton projet.
Au final, l’amélioration de la qualité du code est un processus continu. Le plus important est de toujours garder à l’esprit la simplicité et l’efficacité, tout en utilisant les bons outils et principes au bon moment. En appliquant ces conseils, tu seras en mesure de maintenir un code de haute qualité, évolutif, et facile à maintenir sur le long terme.
Une idée de business en ligne ? Un saas à développer ? Une boutique en ligne à créer ?
Essayer mon-plan-action.fr pour vous aider à démarrer votre projet en ligne.
Alors que Paris se prépare à accueillir les Jeux olympiques de 2024, une autre révolution se prépare en France : celle de la saturation des abonnements. Oui, vous avez bien lu. Avec une moyenne de 3 abonnements par personne, les Français dépensent environ 780 € par an pour des services récurrents. Pas étonnant que 66% d’entre eux jugent qu’il y a trop de services d’abonnement, et 60% déclarent ne pas pouvoir se permettre tous ceux qu’ils souhaitent.
La saturation des abonnements : un problème bien réel 😩
La prolifération des abonnements entraîne des frustrations croissantes :
33% des utilisateurs paient désormais pour des services qui étaient gratuits.
22% consomment du contenu piraté faute d’options tout-en-un abordables.
En tant que développeur, je comprends la nécessité des abonnements pour assurer une source de revenus stable. Cependant, force est de constater que ce modèle atteint ses limites et fatigue les consommateurs.
Le « Super Bundling » : la solution miracle ? 🤔
Le concept de « Super Bundling », qui promet de centraliser et simplifier la gestion des abonnements, attire de plus en plus d’adeptes. Les consommateurs sont même prêts à payer jusqu’à 20 € de plus par mois pour ce service. Mais est-ce vraiment la panacée ?
Réinventons les modèles économiques des SaaS 🌟
Il est temps de penser autrement et de proposer des alternatives viables aux abonnements traditionnels. Voici quatre approches détaillées pour un modèle freemium amélioré :
1. Segmentation des Utilisateurs
Le modèle freemium traditionnel offre généralement une seule version gratuite avec des fonctionnalités limitées. Cette approche unique ne prend pas en compte la diversité des utilisateurs et de leurs besoins spécifiques.
Amélioration :
Diversité des Offres : Proposer plusieurs niveaux de fonctionnalités gratuites adaptées à différents segments d’utilisateurs. Par exemple, une version gratuite pour les particuliers avec des fonctionnalités basiques et une autre pour les petites entreprises avec des outils supplémentaires.
Analyse Comportementale et IA Générative : Utiliser des outils d’analyse avancés et l’intelligence artificielle générative pour comprendre les comportements des utilisateurs et personnaliser les recommandations de fonctionnalités payantes. Ainsi, chaque utilisateur reçoit des suggestions pertinentes, augmentant la probabilité de conversion vers les options payantes.
2. Personnalisation et Adaptabilité
Dans le modèle freemium traditionnel, les utilisateurs gratuits et payants ont souvent des parcours d’utilisation distincts, ce qui peut créer une expérience fragmentée.
Amélioration :
Personnalisation de l’Expérience : Offrir une expérience utilisateur personnalisée même pour les utilisateurs gratuits, en adaptant l’interface et les recommandations en fonction de leurs préférences et usages. L’IA générative peut jouer un rôle clé en créant des expériences uniques pour chaque utilisateur, en fournissant des contenus et des fonctionnalités sur mesure.
Flexibilité des Essais : Permettre des essais gratuits basés sur l’utilisation plutôt que sur une période fixe. Par exemple, offrir un accès temporaire à des fonctionnalités premium en fonction de l’engagement et de l’utilisation du service par l’utilisateur.
3. Fonctionnalités Freemium Plus Riches
Le modèle freemium traditionnel limite souvent les fonctionnalités gratuites à un point où elles deviennent peu utiles, ce qui peut freiner l’adoption et frustrer les utilisateurs.
Amélioration :
Fonctionnalités Robustes : Offrir des fonctionnalités gratuites suffisamment puissantes pour résoudre des problèmes réels, tout en montrant clairement la valeur ajoutée des options payantes. Par exemple, offrir des capacités d’analyse de base gratuitement, mais des analyses avancées sous forme payante.
Éducation et Support : Investir dans l’éducation des utilisateurs gratuits à travers des tutoriels, des webinaires et des supports interactifs. Cela permet de démontrer comment les fonctionnalités payantes peuvent optimiser leur expérience, tout en offrant un support limité mais efficace pour les utilisateurs gratuits.
Gamification : Introduire des éléments de gamification pour encourager l’engagement et la fidélisation. Les utilisateurs peuvent accumuler des points, gagner des badges et obtenir des récompenses pour leur utilisation continue et leur interaction avec le service. Par exemple, des défis hebdomadaires ou mensuels pourraient inciter les utilisateurs à explorer davantage de fonctionnalités, avec des récompenses sous forme d’accès temporaire à des fonctionnalités premium.
Conclusion : Vers un avenir plus flexible et transparent 🌍
Le modèle d’abonnement est en train de montrer ses limites et il est temps d’innover. Les entreprises SaaS doivent explorer des alternatives pour rester compétitives et répondre aux besoins changeants des consommateurs. En réinventant le modèle freemium de manière à offrir une expérience personnalisée et flexible, avec des options payantes à la carte, nous pouvons maximiser la satisfaction des utilisateurs et faciliter la conversion vers les versions premium. Cette approche permet de créer une expérience utilisateur plus engageante et alignée avec les besoins des différents segments de marché.
La révolution des abonnements est en marche, et nous avons l’opportunité de la façonner de manière à ce qu’elle profite à tous💡
En bonus : Cheat Sheet - Modern Saas for Dummies 🛠️
1. Expérience Sur Mesure
Personnalisation : Adaptation des fonctionnalités gratuites et des recommandations en fonction des comportements et des préférences des utilisateurs.
Segmentation : Offrir différentes versions gratuites adaptées à des segments spécifiques (particuliers, petites entreprises, etc.).
2. Options Payantes à la Carte
Flexibilité : Les utilisateurs peuvent choisir et payer uniquement pour les fonctionnalités premium dont ils ont réellement besoin.
Modularité : Les fonctionnalités premium sont disponibles de manière modulaire, permettant aux utilisateurs de composer leur propre expérience en fonction de leurs besoins spécifiques.
3. Engagement et Éducation
Support et Tutoriels : Offrir des ressources éducatives et du support pour aider les utilisateurs à comprendre et à tirer le meilleur parti des fonctionnalités gratuites, tout en montrant la valeur des options premium.
Gamification et Récompenses : Utiliser des mécanismes de gamification pour encourager l’utilisation régulière et la transition vers les fonctionnalités payantes.
4. Essais Flexibles
Essais Non Limités dans le Temps : Proposer des essais gratuits basés sur l’utilisation (nombre d’utilisations) plutôt que sur une période fixe.
Promotions et Offres Temporaires : Offrir des promotions ciblées et des réductions pour les utilisateurs actifs de la version gratuite.
5. Communauté et Support Collaboratif
Forums et Groupes : Créer des espaces de discussion où les utilisateurs gratuits peuvent échanger des conseils et des astuces.
Sessions Q&A : Organiser des sessions de questions-réponses en direct pour aider les utilisateurs à résoudre leurs problèmes et découvrir les avantages des fonctionnalités payantes.
Une idée de business en ligne ? Un saas à développer ? Une boutique en ligne à créer ?
Essayer mon-plan-action.fr pour vous aider à démarrer votre projet en ligne.
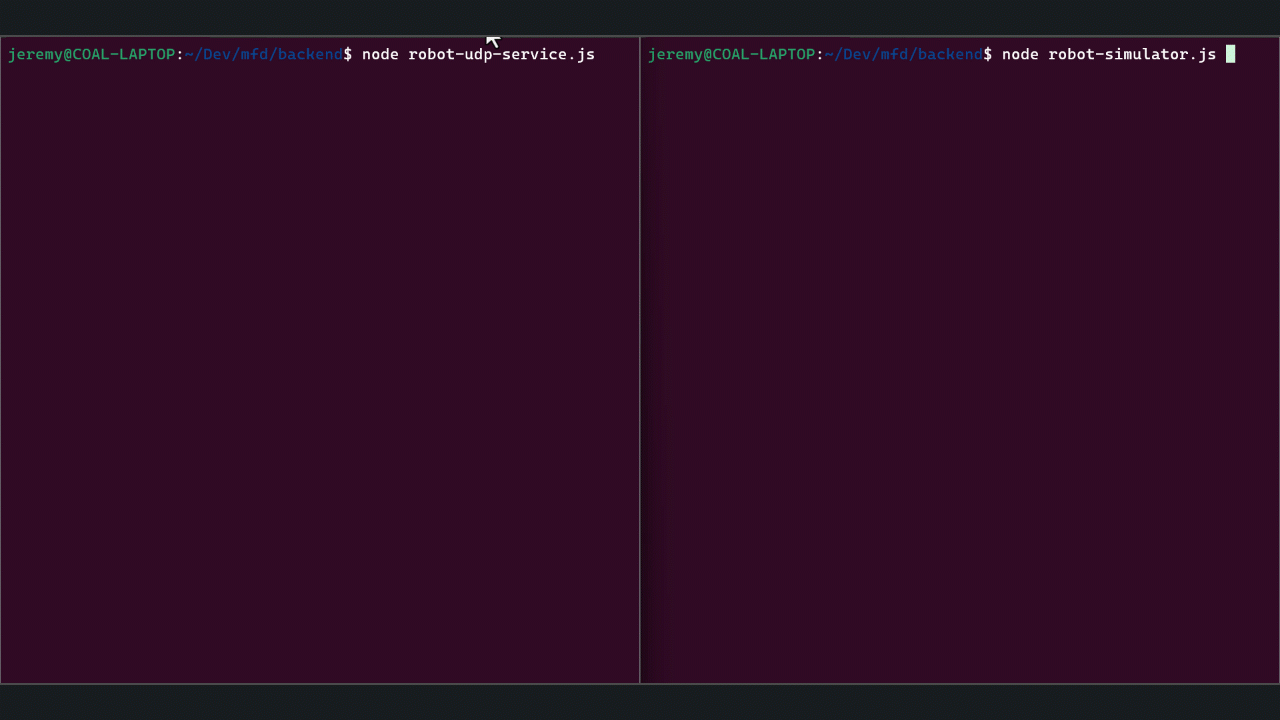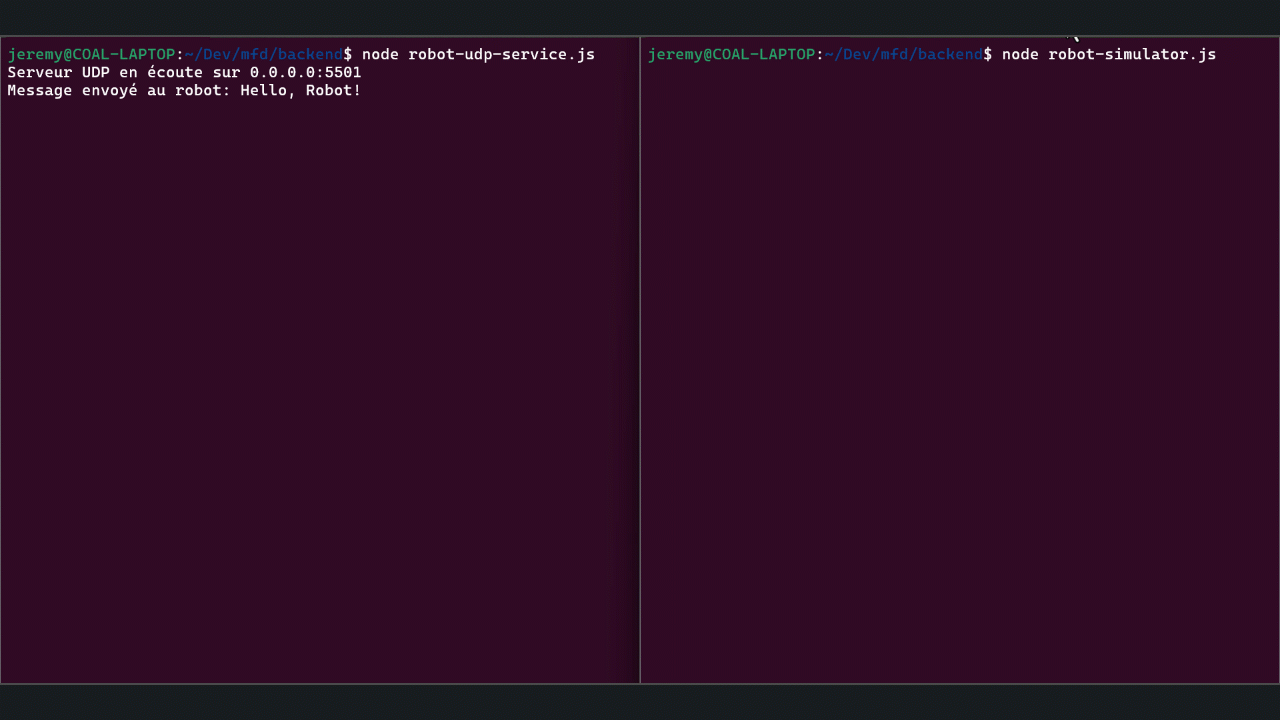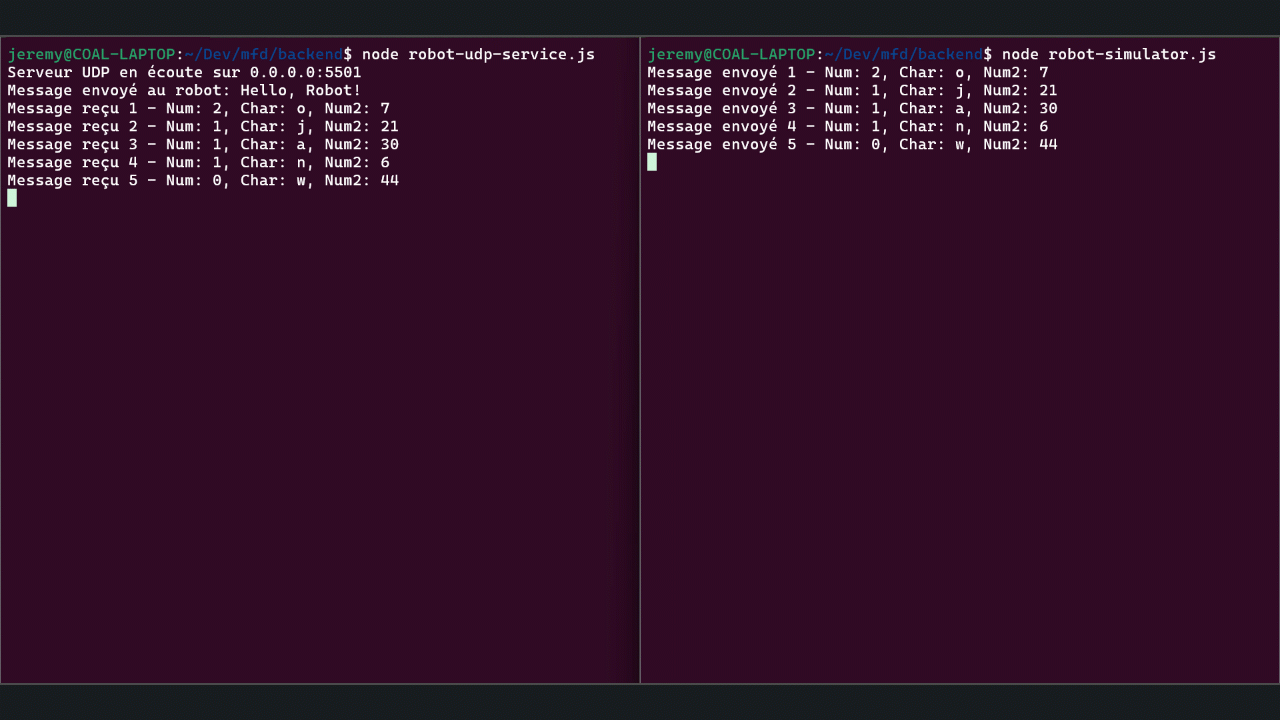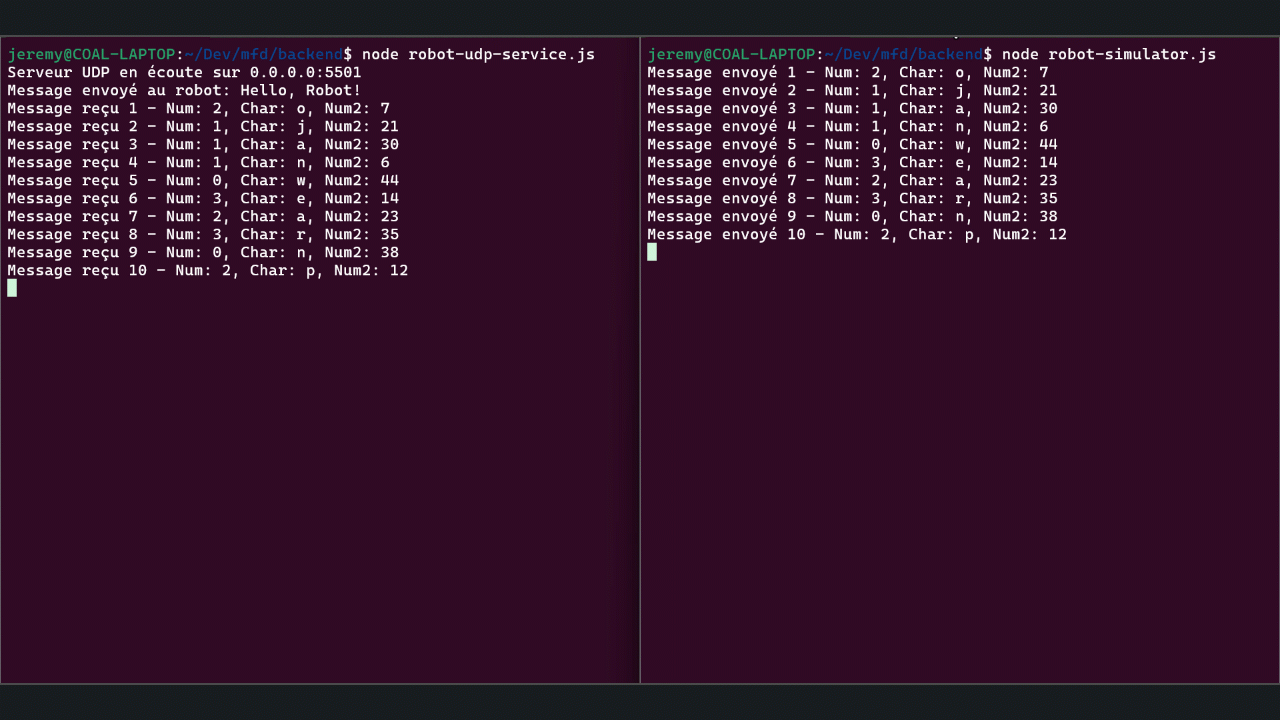
Dans le cadre de l’un de mes projets, je dois développer un logiciel backend Node.js capable de dialoguer avec un robot en utilisant le protocole UDP (User Datagram Protocol).
Nous allons donc voir dans cet article comment mettre en place cette communication en utilisant deux scripts JavaScript : l’un pour simuler l’envoi des données par le robot robot-simulator.js et l’autre pour recevoir ces données robot-udp-service.js. Nous allons détailler ces scripts et expliquer leur fonctionnement.
Cette solution permet de transmettre des données optimisées, minimisant ainsi la taille des paquets pour une communication efficace et rapide.
Le Protocole UDP
UDP est un protocole de communication rapide mais non fiable. Contrairement à TCP, il n’assure pas la livraison des paquets et ne garantit pas leur ordre. Cependant, sa rapidité en fait un excellent choix pour des applications temps réel ou où la vitesse est cruciale.
Diagramme Séquentiel de la Communication
Explication de la Structure des Données
Les données, au niveau du robot, sont optimisées pour minimiser la taille des paquets envoyés. Voici comment les données sont structurées sur deux octets :
Octet 1
Bits 0-1 : num1
Bits 2-7 : charCode (6 bits)
Octet 2
Bits 0-1 : charCode (suite, 2 bits)
Bits 2-7 : num2
num1 : un nombre entre 0 et 3, codé sur 2 bits. charCode : le code ASCII d’un caractère (a-z), codé sur 8 bits (6 bits dans le premier octet, 2 bits dans le second). num2 : un nombre entre 0 et 63, codé sur 6 bits dans le second octet.
Il va donc falloir restructurer ses données pour les exploiter dans le service de réception. Nous allons pour cela utiliser des techniques de décalage et de masquage de bits pour extraire les différentes parties des octets.
Script de Simulation du Robot : robot-simulator.js
Ce script simule le comportement du robot en envoyant des messages UDP structurés au service de réception.
// Importation du module 'dgram' pour créer des sockets UDP const dgram = require('dgram'); // Création d'un socket UDP const socket = dgram.createSocket('udp4');
// Adresse IP et port du service de réception constSERVICE_IP = '127.0.0.1'; constSERVICE_PORT = 5501;
let messageCount = 0; // Compteur pour les messages envoyés
// Fonction pour générer un entier aléatoire entre 'min' et 'max' functiongetRandomInt(min, max) { returnMath.floor(Math.random() * (max - min + 1)) + min; }
// Fonction pour créer un message structuré functioncreateStructuredMessage() { let buffer = Buffer.alloc(2);
// Génération des données let num1 = getRandomInt(0, 3); // Nombre entre 0 et 3 let charCode = getRandomInt(97, 122); // Code ASCII pour une lettre minuscule (a-z) let char = String.fromCharCode(charCode); // Conversion du code ASCII en caractère let num2 = getRandomInt(0, 63); // Nombre entre 0 et 63
// Premier octet : bits 0-1 pour 'num1', bits 2-7 pour 'charCode' (6 premiers bits) buffer[0] = (num & 0b11) | ((charCode & 0b111111) << 2);
// Deuxième octet : bits 0-1 pour 'charCode' (2 derniers bits), bits 2-7 pour 'num2' buffer[1] = ((charCode >> 6) & 0b11) | ((num2 & 0b111111) << 2);
return { buffer, num1, char, num2 }; }
// Fonction pour envoyer un message structuré au service functionsendMessageToService(buffer, serviceIp, servicePort, num1, char, num2) { messageCount++; socket.send(buffer, servicePort, serviceIp, (err) => { if (err) { console.error('Erreur lors de l\'envoi du message:', err); } else { console.log(`Message envoyé ${messageCount} - Num1: ${num1}, Char: ${char}, Num2: ${num2}`); } }); }
// Envoi périodique de messages structurés toutes les 500 millisecondes setInterval(() => { const { buffer, num1, char, num2 } = createStructuredMessage(); sendMessageToService(buffer, SERVICE_IP, SERVICE_PORT, num1, char, num2); }, 500);
// Gestion des erreurs du socket socket.on('error', (err) => { console.error('Erreur du socket:', err); socket.close(); });
// Gestion de la fermeture du socket socket.on('close', () => { console.log('Socket fermé'); });
Script de Réception des Données : robot-udp-service.js
Ce script écoute les messages UDP envoyés par le robot. Il décode les messages structurés et affiche les données reçues.
// Importation du module 'dgram' pour créer des sockets UDP const dgram = require('dgram'); // Création d'un socket UDP const socket = dgram.createSocket('udp4');
// Adresses IP et ports pour la communication avec le robot et le service local constROBOT_IP = '10.5.0.2'; constROBOT_PORT = 6501;
let messageCount = 0; // Compteur pour les messages reçus
// Fonction pour envoyer un message au robot functionsendMessageToRobot(message, robotIp, robotPort) { const messageBuffer = Buffer.from(message); socket.send(messageBuffer, robotPort, robotIp, (err) => { if (err) { console.error('Erreur lors de l\'envoi du message:', err); } else { console.log('Message envoyé au robot:', message); } }); }
// Fonction pour décoder un message structuré reçu functionparseStructuredMessage(buffer) { // Premier octet : extraction des 2 premiers bits pour 'num1' et des 6 suivants pour 'charCode' let num1 = buffer[0] & 0b11; let charCode = (buffer[0] >> 2) & 0b111111;
// Deuxième octet : extraction des 2 premiers bits restants de 'charCode' et des 6 bits suivants pour 'num2' charCode |= (buffer[1] & 0b11) << 6; let num2 = (buffer[1] >> 2) & 0b111111;
let char = String.fromCharCode(charCode);
return { num1, char, num2 }; }
// Fonction pour gérer la réception des messages functionhandleIncomingMessage(msg, rinfo) { const parsedMessage = parseStructuredMessage(msg); messageCount++; console.log(`Message reçu ${messageCount} - Num1: ${parsedMessage.num1}, Char: ${parsedMessage.char}, Num2: ${parsedMessage.num2}`); }
// Configuration de l'événement 'message' pour le socket socket.on('message', handleIncomingMessage);
// Liaison du socket à une adresse IP et un port locaux socket.bind(LOCAL_PORT, LOCAL_IP, () => { console.log(`Serveur UDP en écoute sur ${LOCAL_IP}:${LOCAL_PORT}`); });
// Envoi d'un message initial au robot sendMessageToRobot('Hello, Robot!', ROBOT_IP, ROBOT_PORT);
// Gestion des erreurs du socket socket.on('error', (err) => { console.error('Erreur du socket:', err); socket.close(); });
// Gestion de la fermeture du socket socket.on('close', () => { console.log('Socket fermé'); });
Exécution des Scripts
Conclusion
Ces scripts montrent comment envoyer et recevoir des messages UDP structurés en Node.js. Cette technique peut être adaptée pour divers types de communication en temps réel où la rapidité est cruciale. En suivant et adaptant ces exemples, vous pourrez implémenter des solutions similaires pour vos propres projets.
Une idée de business en ligne ? Un saas à développer ? Une boutique en ligne à créer ?
Essayer mon-plan-action.fr pour vous aider à démarrer votre projet en ligne.
Dans cet article, nous allons transformer un Raspberry Pi 4 sous Ubuntu 22.04 LTS en point d’accès Wi-Fi, une solution puissante et flexible pour de nombreuses applications. Cela devrait aussi fonctionner avec un Raspberry Pi 5 sous Ubuntu 24.04 LTS.
À la fin de cet article, vous serez capable de mettre en place votre propre point d’accès Wi-Fi chez vous.
Pourquoi Créer un Point d’Accès Wi-Fi avec un Raspberry Pi ?
Créer un point d’accès Wi-Fi avec un Raspberry Pi présente plusieurs avantages :
Coût réduit : Un Raspberry Pi est une solution abordable comparée à des routeurs commerciaux.
Flexibilité : Vous pouvez personnaliser votre configuration selon vos besoins spécifiques.
Apprentissage : C’est une excellente opportunité pour apprendre davantage sur les réseaux et Linux.
Exemples d’Utilisation
Étendre la couverture Wi-Fi : Améliorez la couverture de votre réseau Wi-Fi dans les zones mortes.
Réseau invité : Fournissez un réseau séparé pour vos invités sans compromettre la sécurité de votre réseau principal.
Projets IoT : Créez un réseau dédié pour vos appareils IoT.
Objectifs de Cet Article
Nous allons :
Configurer un Raspberry Pi en point d’accès Wi-Fi.
Comprendre le rôle de hostapd, dnsmasq et netplan dans cette configuration.
Fournir un script pour visualiser le fonctionnement du point d’accès.
Prérequis
Un Raspberry Pi 4 ou 5 avec Ubuntu 22.04 LTS ou 24.04 LTS installé.
Une connexion Internet pour installer les paquets nécessaires.
Étapes de Configuration
1. Installation et Mise à Jour
Tout d’abord, mettons à jour notre Raspberry Pi et installons les paquets nécessaires :
Hostapd : Utilisé pour créer un point d’accès Wi-Fi.
Dnsmasq : Fournit les services DHCP et DNS.
Netplan : Utilisé pour la configuration réseau sur Ubuntu.
Schéma Fonctionnel
Conclusion
Transformer un Raspberry Pi en point d’accès Wi-Fi est une solution économique et flexible pour divers besoins réseau. Avec les instructions ci-dessus, vous devriez être en mesure de configurer votre propre point d’accès Wi-Fi à la maison. Que ce soit pour étendre la couverture Wi-Fi, créer un réseau pour invités, ou pour vos projets IoT, cette configuration offre de nombreuses possibilités.
Une idée de business en ligne ? Un saas à développer ? Une boutique en ligne à créer ?
Essayer mon-plan-action.fr pour vous aider à démarrer votre projet en ligne.
Ce projet est une application web de type Single Page Application (SPA) développée avec Svelte et Vite. Il sert de base de départ pour la réalisation d’applications SPA.
Il existe aussi une version backend de l’ossature : Fluxx Backend.
Stack technologique
Svelte
Svelte est un framework JavaScript moderne qui permet de créer des interfaces utilisateur réactives. Svelte compile les composants en JavaScript optimisé au moment de la construction, ce qui permet un rendu ultra-rapide et une interaction fluide. Contrairement à d’autres frameworks, Svelte n’inclut pas de runtime ou bibliothèque volumineuse dans le bundle final, ce qui réduit la taille des fichiers JavaScript envoyés au navigateur.
Vite
Vite est un bundler et serveur de développement rapide, qui offre une excellente expérience de développement. Vite révolutionne le flux de travail du développement web avec sa rapidité, sa simplicité de configuration et son support des technologies modernes. Il améliore l’expérience des développeurs grâce à des temps de démarrage instantanés, des mises à jour à chaud rapides, et une compatibilité étendue avec différents frameworks front-end, faisant de lui un choix idéal pour les projets web modernes.
Intégration de la Stack
L’intégration de Svelte et Vite offre une solution puissante et efficace pour le développement d’applications web modernes. Svelte, avec sa syntaxe concise et ses performances optimisées, combiné à Vite, avec son démarrage instantané et son Hot Module Replacement ultra-rapide, permet de créer des applications réactives et performantes avec une expérience développeur exceptionnelle. Cette combinaison réduit les temps de build et simplifie la configuration, tout en offrant une flexibilité maximale grâce à la compatibilité avec les fonctionnalités modernes et divers frameworks front-end. Ensemble, Svelte et Vite forment une stack de développement idéale pour des projets rapides, maintenables et à hautes performances.
Structure du projet
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
frontend/ ├── public/ # Contient les ressources publiques telles que les images, les manifestes, etc. ├── src/ # Contient le code source de l'application │ ├── components/ # Composants réutilisables de Svelte │ ├── lib/ # Modules d'aide et stores Svelte │ ├── routes/ # Composants de routage pour différentes pages │ ├── style/ # Fichiers de style SCSS │ ├── App.svelte # Composant principal de l'application │ ├── config.example.js # Exemple de configuration de l'application │ └── main.js # Point d'entrée de l'application ├── .nvmrc # Version de Node.js à utiliser ├── eslint.config.mjs # Configuration d'ESLint ├── jsconfig.json # Configuration de JavaScript pour le projet ├── package.json # Dépendances et scripts du projet ├── svelte.config.js # Configuration de Svelte ├── vite.config.js # Configuration de Vite ├── remoteDeploy.example.sh # Exemple de script pour déployer en production └── README.md # Documentation du projet
Diagramme séquentiel du flux d’authentification de l’utilisateur
Installation
Pour installer et exécuter le projet en local, suivez les étapes suivantes :
Cloner le dépôt
1 2
git clone git@deployment:jeremydierx/fluxx-frontend.git cd fluxx-frontend
Installer les dépendances
1
npm install
** Adapter les fichiers de configuration à vos besoins**
L’application sera accessible à l’adresse https://localhost:[port] où [port] est le port configuré dans le fichier vite.config.js.
Génération de la documentation intégrée (JSDoc)
1
$ npm run docs
Linting
1
$ npm run lint
En distant (serveur de production)
Commandes de Déploiement pour l’Environnement de Production
1
$ npm run remoteDeployProd
Commandes de Maintenance pour l’Environnement de Production
1 2
$ npm run remoteMaintenanceOnProd # Activer le mode maintenance $ npm run remoteMaintenanceOffProd # Désactiver le mode maintenance
Pourquoi je n’utilise pas de framework «tout-en-un» ?
Apprentissage en Profondeur:
Masquage de la Complexité : Les frameworks tout-en-un ont tendance à abstraire beaucoup de complexités, ce qui peut empêcher les développeurs d’apprendre et de comprendre les mécanismes sous-jacents. Cette abstraction peut limiter la capacité des développeurs à résoudre des problèmes complexes ou à optimiser les performances de manière efficace.
Dépendance au Framework : Une dépendance excessive à un framework spécifique peut restreindre la flexibilité des développeurs et les rendre moins adaptables à d’autres technologies ou paradigmes.
Surcharge Fonctionnelle:
Overkill pour les Projets Simples : Ces frameworks viennent souvent avec une multitude de fonctionnalités intégrées qui peuvent être superflues pour de nombreux projets, rendant la configuration initiale et la maintenance plus lourdes et complexes.
Performance Impactée : L’inclusion de fonctionnalités non nécessaires peut alourdir l’application et impacter ses performances, surtout si ces fonctionnalités ne sont pas utilisées mais continuent de consommer des ressources.
Flexibilité Limitée:
Personnalisation Difficile : La personnalisation ou l’extension des fonctionnalités d’un framework tout-en-un peut être difficile ou impossible sans recourir à des hacks ou des contournements, ce qui peut nuire à la maintenabilité du code.
Contraintes architecturales : Ces frameworks imposent souvent une architecture et une structure spécifiques, limitant la capacité des développeurs à adapter l’application à des besoins uniques ou à adopter des meilleures pratiques qui sortent du cadre défini par le framework.
Le principe KIS (Keep It Simple)
Le principe KIS (Keep It Simple) prône la simplicité et l’absence de complexité inutile dans le développement et la conception. En privilégiant des solutions directes et faciles à comprendre, ce principe facilite la maintenance, réduit les erreurs et améliore l’efficacité. En se concentrant sur l’essentiel et en éliminant les éléments superflus, KIS permet de créer des systèmes plus robustes, plus accessibles et plus rapides à mettre en œuvre. Adopter KIS aide les équipes à rester agiles, à réduire les coûts et à livrer des produits de qualité supérieure en évitant les complications inutiles.
Éviter la programmation orientée objet (POO)
Préférez les fonctions et les structures de données simples aux classes et objets complexes pour réduire la complexité du code.
Utiliser JSDOC à la place de TypeScript
Documentez votre code JavaScript avec JSDoc pour bénéficier de l’auto-complétion et de la vérification des types, sans la complexité supplémentaire de TypeScript.
Privilégier les solutions simples
Choisissez toujours la solution la plus simple et directe pour résoudre un problème, même si elle semble moins élégante ou moins sophistiquée.
Éviter les abstractions inutiles
Limitez l’utilisation des abstractions (comme les interfaces, les frameworks complexes) qui peuvent rendre le code plus difficile à comprendre et à maintenir.
Utiliser des noms de variables et de fonctions explicites
Choisissez des noms clairs et significatifs pour vos variables et fonctions afin de rendre le code auto-documenté.
Diviser le code en petites fonctions
Écrivez des fonctions courtes et spécifiques qui effectuent une seule tâche, ce qui facilite la compréhension et la maintenance.
Minimiser les dépendances
Réduisez le nombre de bibliothèques et de frameworks externes pour limiter les points de défaillance et simplifier la gestion des mises à jour.
Favoriser la composition plutôt que l’héritage
Utilisez la composition de fonctions et de modules au lieu de l’héritage pour structurer votre code, ce qui permet de réutiliser et de tester plus facilement les composants.
Écrire des tests simples et clairs
Rédigez des tests unitaires et d’intégration qui sont faciles à comprendre et à maintenir, couvrant les cas d’utilisation principaux sans surcharger le projet.
Limiter les commentaires
Évitez de commenter chaque ligne de code. Utilisez des commentaires uniquement lorsque cela est nécessaire pour expliquer des choix non évidents.
Utiliser des outils de linters
Employez des outils de linting comme ESLint pour automatiser la vérification de la qualité et la cohérence du code.
Suivre les conventions de code
Adoptez et respectez des conventions de codage claires et bien définies pour maintenir un code cohérent et lisible par tous les membres de l’équipe.
Éviter les optimisations prématurées
Ne vous concentrez pas sur l’optimisation du code avant de vérifier qu’il y a effectivement un problème de performance. Priorisez la simplicité et la clarté.
Favoriser l’utilisation de l’outillage standard
Utilisez les fonctionnalités natives du langage et des environnements de développement avant de recourir à des solutions externes ou sur-mesure.
Conclusion
En suivant ces principes KIS, vous pourrez créer des systèmes plus simples, plus robustes et plus faciles à maintenir, tout en réduisant les coûts et le temps de développement.
Fluxx Frontend est disponible sur GitHub sous licence MIT.
Une idée de business en ligne ? Un saas à développer ? Une boutique en ligne à créer ?
Essayer mon-plan-action.fr pour vous aider à démarrer votre projet en ligne.