
Vous avez un kernel temps réel mais vos threads se bloquent encore ?
Dans mon article précédent sur le kernel temps réel, nous avons configuré un Raspberry Pi 4 avec RT_PREEMPT pour obtenir des latences garanties sous les 100 µs.
Mais un kernel temps réel ne suffit pas : il faut aussi éviter les mécanismes de synchronisation qui bloquent.
Aujourd’hui, je vous présente les ring buffers lock-free, la solution pour une communication inter-threads sans aucun blocage, parfaite pour le temps réel strict.
Le problème des mutex et sémaphores en temps réel
Scénario catastrophe : l’inversion de priorité
Prenons le cas de deux threads :
| Thread | Priorité | Rôle |
|---|---|---|
| Thread A | 80 (haute) | Master EtherCAT, cycle de 1 ms |
| Thread B | 60 (basse) | Communication UDP avec PC |
Les deux threads partagent des données via un mutex. Voici ce qui peut se passer :
1 | t=0ms : Thread B (prio 60) acquiert le mutex |
C’est l’inversion de priorité : le thread haute priorité est bloqué par un thread basse priorité. En temps réel, c’est inacceptable.
Les coûts cachés des verrous
Même avec des mécanismes avancés (priority inheritance), les verrous ont des inconvénients majeurs :
| Mécanisme | Problème principal | Impact temps réel |
|---|---|---|
| Mutex | Inversion de priorité | Latence imprévisible |
| Sémaphore | Appels système (syscalls) | Latence de plusieurs µs |
| Spinlock | Gaspillage CPU (busy-wait) | Mauvais sur multi-core |
| Priority inheritance | Complexe, overhead | Latence réduite mais présente |
Le constat : Aucun verrou ne garantit zéro blocage ni latence constante en O(1).
La solution : Ring Buffer Lock-Free
Principe fondamental
Un ring buffer lock-free (Single Producer Single Consumer - SPSC) repose sur deux règles simples :
✅ UN SEUL producteur écrit dans le buffer
✅ UN SEUL consommateur lit depuis le buffer
Avec ces contraintes, on peut utiliser des indices atomiques sans aucun verrou :
1 | write_idx (atomique) |
Pourquoi ça fonctionne ?
La magie réside dans les opérations atomiques C11 :
- memory_order_acquire : Garantit que les lectures ne se réordonnent pas avant
- memory_order_release : Garantit que les écritures ne se réordonnent pas après
- memory_order_relaxed : Lecture simple sans contrainte de synchronisation
Ces garanties sont matérielles (barrières mémoire CPU), pas logicielles. Résultat : O(1) constant, zéro blocage.
Avantages pour le temps réel
| Caractéristique | Ring Buffer Lock-Free | Mutex/Sémaphore |
|---|---|---|
| Blocage | Jamais | Toujours possible |
| Inversion de priorité | Impossible | Risque élevé |
| Latence | O(1) constante | Imprévisible |
| Appels système | Zéro | Chaque lock/unlock |
| Overhead | ~10 ns | ~1-5 µs |
| Complexité | Simple | Nécessite gestion d’erreurs |
Implémentation détaillée en C
Structure de données
Voici l’implémentation complète du ring buffer :
1 |
|
Points clés :
_Alignas(64): Chaque index est sur sa propre ligne de cache (64 bytes sur ARM Cortex-A72)- Évite le false sharing : quand deux CPUs modifient des données sur la même cache line
atomic_size_t: Type atomique C11, opérations garanties thread-safe
Initialisation
1 | void ringbuf_init(ringbuf_t *rb) |
Rien de spécial ici, on met tout à zéro.
Écriture (producteur)
1 | bool ringbuf_write(ringbuf_t *rb, const message_t *msg) |
Analyse ligne par ligne :
memory_order_acquiresurread_idx: On veut voir les dernières lectures du consommateur- Écriture normale du message : Pas besoin d’atomique, un seul producteur
memory_order_releasesurwrite_idx: Garantit que le message est écrit AVANT que l’index soit publié
Lecture (consommateur)
1 | bool ringbuf_read(ringbuf_t *rb, message_t *msg) |
Symétrique à l’écriture :
memory_order_acquiresurwrite_idx: On veut voir les dernières écritures du producteur- Lecture normale du message
memory_order_releasesurread_idx: Publie qu’on a lu le message
Pourquoi memory_order_acquire et release ?
C’est la clé de la synchronisation lock-free :
1 | PRODUCTEUR CONSOMMATEUR |
Le RELEASE du producteur synchronise avec l’ACQUIRE du consommateur, garantissant que le message est visible.
Exemple pratique : Communication bidirectionnelle
Le programme d’exemple démontre une communication bidirectionnelle entre deux threads en utilisant deux ring buffers :
1 | Thread A (prio 80) Thread B (prio 60) |
Architecture du test
| Thread | Priorité | CPU | Période | Message |
|---|---|---|---|---|
| Thread A | 80 (SCHED_FIFO) | 2 isolé | 1 seconde | “ping” |
| Thread B | 60 (SCHED_FIFO) | 3 isolé | 3 secondes | “pong” |
Observation attendue : Thread A envoie 3 messages pour chaque message de B (ratio 1s/3s), sans jamais se bloquer.
Boucle principale du thread A
1 | while (running) { |
Points importants :
ringbuf_readretourne immédiatement si pas de message (non-bloquant)ringbuf_writeretourne immédiatement si buffer plein (non-bloquant)- Aucun appel système de synchronisation
- Le thread garde le contrôle total de son ordonnancement
Sortie du programme
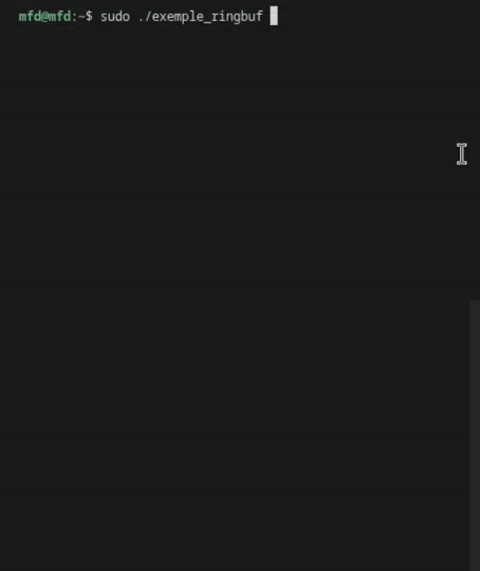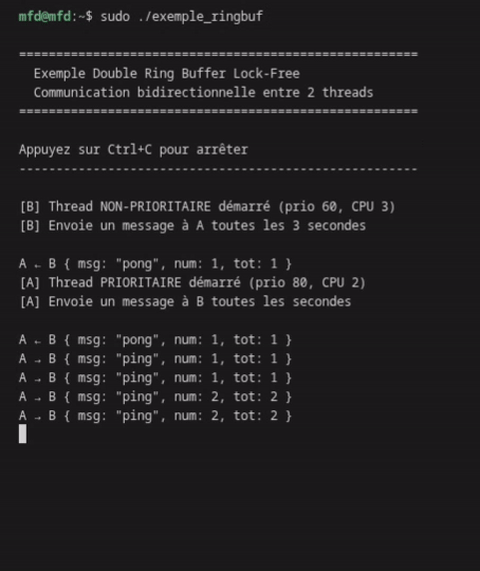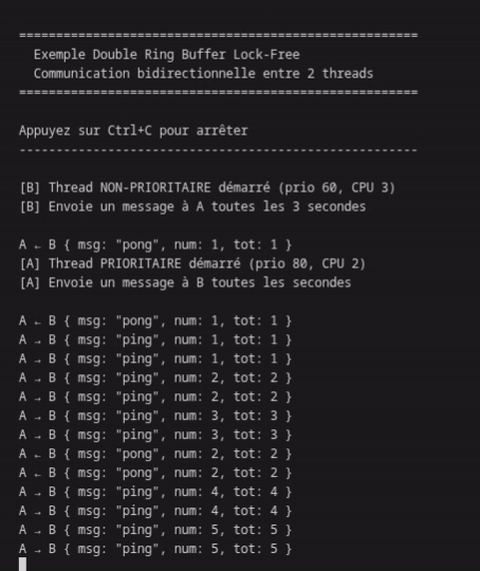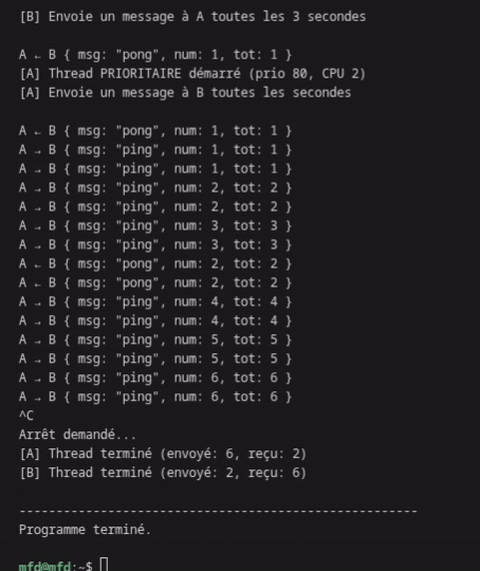
La communication est fluide, sans blocage, avec un ratio 3:1 comme attendu.
Performance et garanties temps réel
Mesures de latence
Sur Raspberry Pi 4 avec kernel RT_PREEMPT :
| Opération | Latence | Comparaison |
|---|---|---|
ringbuf_write() |
~15-20 ns | Mutex: ~1-5 µs (100x plus lent) |
ringbuf_read() |
~15-20 ns | Sémaphore: ~2-8 µs (150x plus lent) |
| Overhead total | O(1) constant | Mutex: imprévisible |
Garanties temps réel
✅ Jamais de blocage : Les opérations retournent immédiatement
✅ Latence constante : O(1) indépendante de la charge
✅ Pas d’inversion de priorité : Pas de verrou = pas d’inversion
✅ Pas d’appel système : Tout en espace utilisateur
✅ Déterminisme garanti : Comportement prévisible à 100%
Cas d’usage idéaux
Le ring buffer lock-free est parfait pour :
- Master EtherCAT : Communication entre thread cycle PDO (1 ms) et thread réseau
- Contrôle moteur : Commandes haute fréquence entre threads
- Acquisition de données : Pipeline producteur/consommateur sans latence
- Audio temps réel : Buffer de samples entre threads DSP
- Robotique : Communication entre contrôleurs et supervision
Limites et précautions
Quand NE PAS utiliser un ring buffer lock-free
❌ Multiple producteurs ou consommateurs : Nécessite des atomiques CAS (Compare-And-Swap), plus complexe
❌ Besoin de notification immédiate : Le consommateur doit poller le buffer
❌ Données de taille variable : Mieux vaut un allocateur lock-free
❌ Priorité stricte FIFO entre >2 threads : Utiliser une queue lock-free multi-producteurs
Précautions d’implémentation
⚠️ Alignement cache line : Toujours aligner les indices atomiques sur 64 bytes
⚠️ Taille buffer = puissance de 2 : Simplifie le modulo avec un masque (% devient & 0x3F)
⚠️ Gestion buffer plein : Décider entre bloquer, abandonner, ou agrandir
⚠️ False sharing : Séparer les données read-only/write-only sur des cache lines différentes
Compilation et test du projet
Le code complet est disponible sur GitHub
Cross-compilation depuis votre PC
1 | # Cloner le projet |
Exécution sur Raspberry Pi
1 | # Se connecter au Raspberry Pi |
Prérequis : Raspberry Pi 4 avec kernel RT_PREEMPT et CPUs 2-3 isolés (voir article précédent)
Conclusion
Les ring buffers lock-free sont la solution idéale pour la communication inter-threads en temps réel strict :
- Zéro blocage : Les threads ne s’attendent jamais
- Latence constante : O(1) indépendante de la charge (15-20 ns)
- Pas d’inversion de priorité : Pas de verrou = pas de problème
- Simplicité : Implémentation en ~50 lignes de C
Combinés avec un kernel RT_PREEMPT et des CPUs isolés, ils permettent d’atteindre un déterminisme total sur Raspberry Pi 4.
Le code complet, abondamment commenté, est disponible sur GitHub et peut servir de base pour vos propres projets temps réel.
Pour aller plus loin
Ressources techniques
- Lock-Free Programming - Preshing
- C11 Atomics Reference
- Memory Ordering at Compile Time
- Article précédent : Kernel RT_PREEMPT sur Raspberry Pi 4
Note : Cet article fait suite à Kernel Temps Réel sur Raspberry Pi 4 : Guide et Tutoriel C++. Si vous n’avez pas encore configuré votre Raspberry Pi avec RT_PREEMPT, commencez par là !
Jérémy @ Code Alchimie